搜索到
42
篇与
资料整理
的结果
-
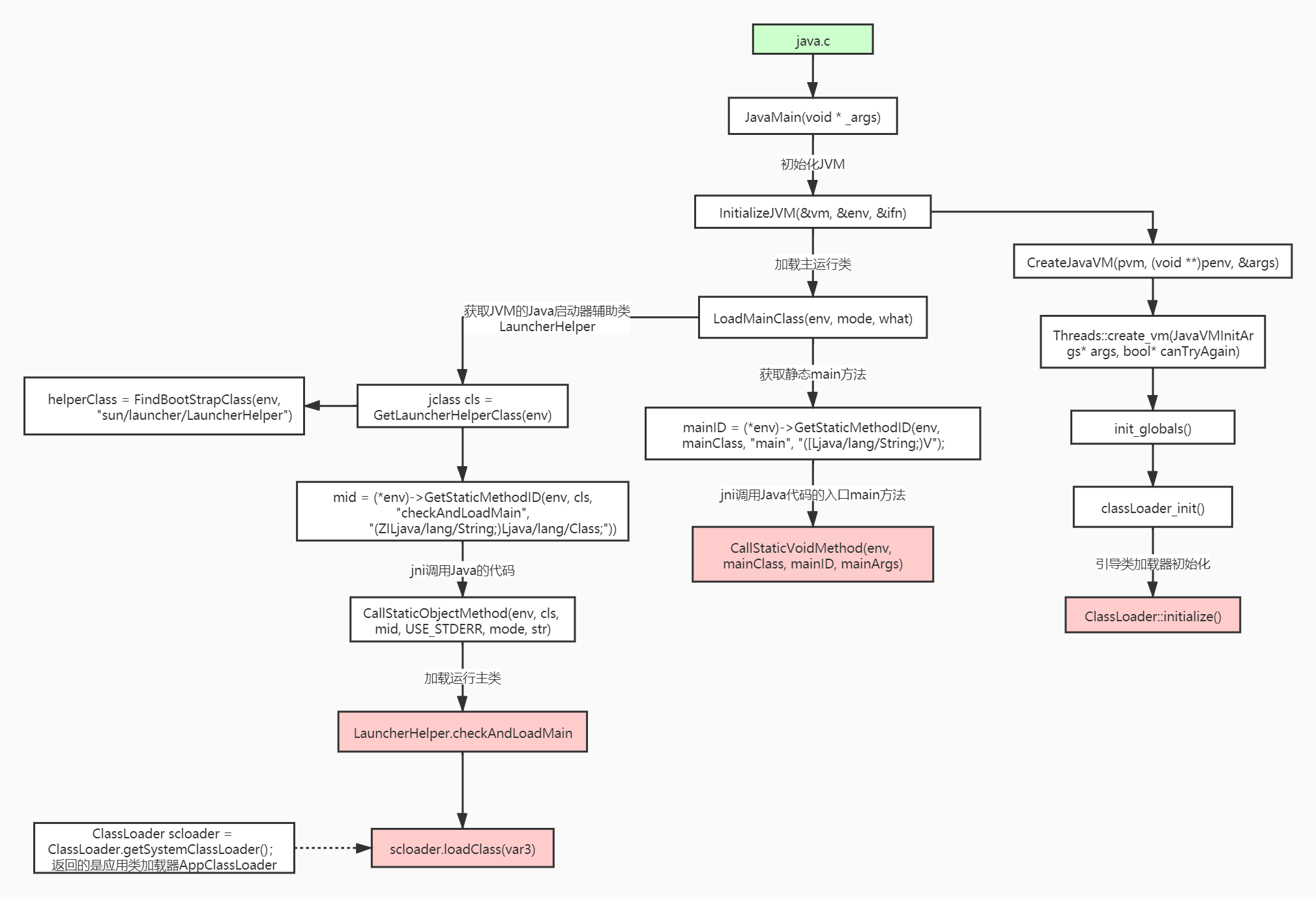
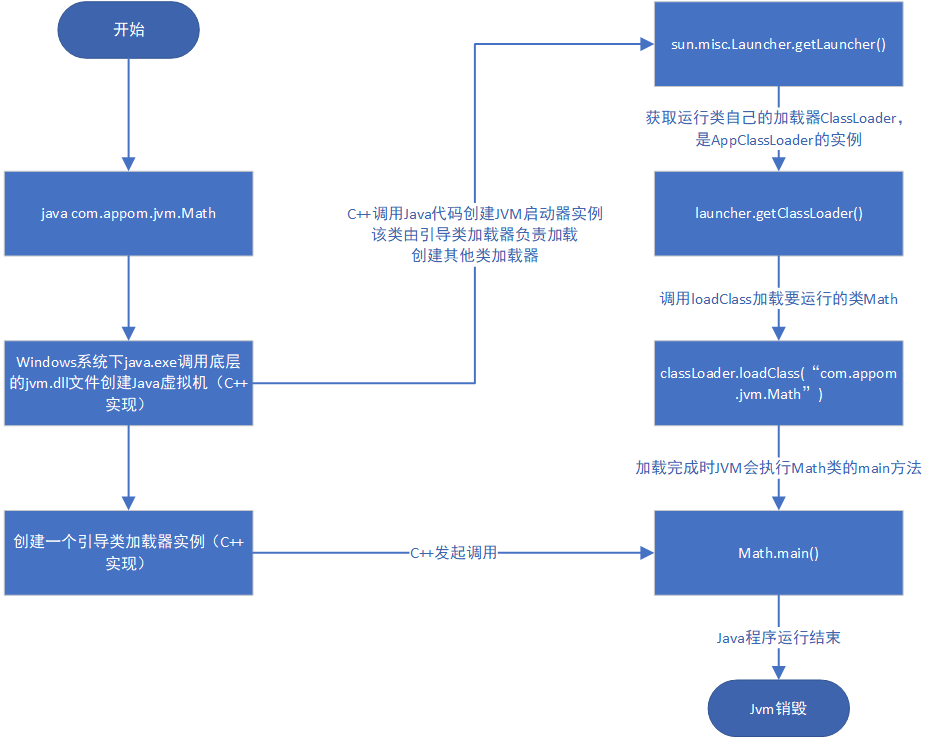
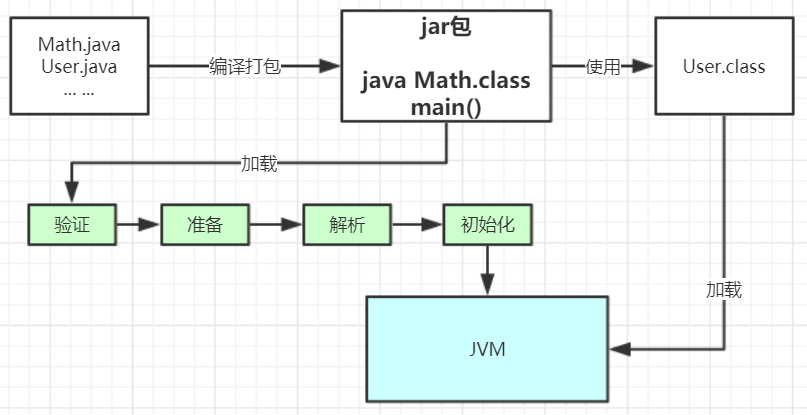
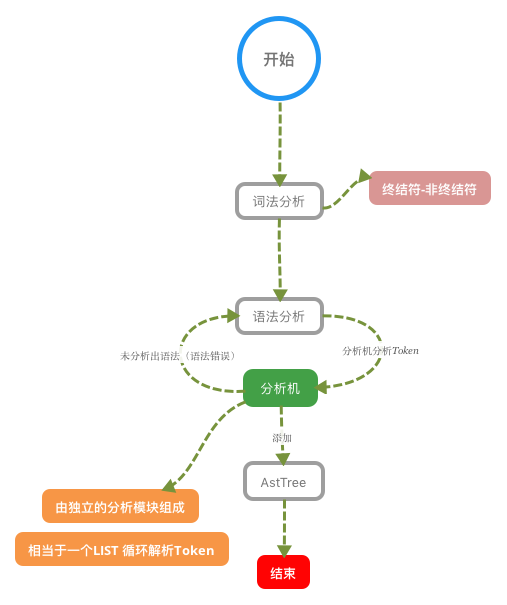
深入理解JVM类加载机制 类加载运行全过程当我们用java命令运行某个类的main函数启动程序时,首先需要通过类加载器把主类加载到JVM。package com.appom.jvm; public class Math { public static final int initData = 666; public static User user = new User(); public int compute() { // 一个方法对应一块栈帧内存区域 int a = 1; int b = 2; int c = (a + b) * 10; return c; } public static void main(String[] args) { Math math = new Math(); math.compute(); } }通过Java命令执行代码的大体流程如下:其中loadClass的类加载过程有如下几步:加载 >> 验证 >> 准备 >> 解析 >> 初始化 >> 使用 >> 卸载加载:在硬盘上查找并通过IO读入字节码文件,使用到类时才会加载,例如调用类的main()方法,new对象等等,在加载阶段会在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口验证:校验字节码文件的正确性准备:给类的静态变量分配内存,并赋予默认值解析:将符号引用替换为直接引用,该阶段会把一些静态方法(符号引用,比如main()方法)替换为指向数据所存内存的指针或句柄等(直接引用),这是所谓的静态链接过程(类加载期间完成),动态链接是在程序运行期间完成的将符号引用替换为直接引用,下节课会讲到动态链接初始化:对类的静态变量初始化为指定的值,执行静态代码块类被加载到方法区中后主要包含 运行时常量池、类型信息、字段信息、方法信息、类加载器的引用、对应class实例的引用等信息。类加载器的引用:这个类到类加载器实例的引用对应class实例的引用:类加载器在加载类信息放到方法区中后,会创建一个对应的Class 类型的对象实例放到堆(Heap)中, 作为开发人员访问方法区中类定义的入口和切入点。注意,主类在运行过程中如果使用到其它类,会逐步加载这些类。jar包或war包里的类不是一次性全部加载的,是使用到时才加载。public class TestDynamicLoad { static { System.out.println("*************load TestDynamicLoad************"); } public static void main(String[] args) { new A(); System.out.println("*************load test************"); B b = null; //B不会加载,除非这里执行 new B() } } class A { static { System.out.println("*************load A************"); } public A() { System.out.println("*************initial A************"); } } class B { static { System.out.println("*************load B************"); } public B() { System.out.println("*************initial B************"); } } 运行结果: *************load TestDynamicLoad************ *************load A************ *************initial A************ *************load test************类加载器和双亲委派机制上面的类加载过程主要是通过类加载器来实现的,Java里有如下几种类加载器引导类加载器:负责加载支撑JVM运行的位于JRE的lib目录下的核心类库,比如rt.jar、charsets.jar等扩展类加载器:负责加载支撑JVM运行的位于JRE的lib目录下的ext扩展目录中的JAR类包应用程序类加载器:负责加载ClassPath路径下的类包,主要就是加载你自己写的那些类自定义加载器:负责加载用户自定义路径下的类包看一个类加载器示例:public class TestJDKClassLoader { public static void main(String[] args) { System.out.println(String.class.getClassLoader()); System.out.println(com.sun.crypto.provider.DESKeyFactory.class.getClassLoader().getClass().getName()); System.out.println(TestJDKClassLoader.class.getClassLoader().getClass().getName()); System.out.println(); ClassLoader appClassLoader = ClassLoader.getSystemClassLoader(); ClassLoader extClassloader = appClassLoader.getParent(); ClassLoader bootstrapLoader = extClassloader.getParent(); System.out.println("the bootstrapLoader : " + bootstrapLoader); System.out.println("the extClassloader : " + extClassloader); System.out.println("the appClassLoader : " + appClassLoader); System.out.println(); System.out.println("bootstrapLoader加载以下文件:"); URL[] urls = Launcher.getBootstrapClassPath().getURLs(); for (int i = 0; i < urls.length; i++) { System.out.println(urls[i]); } System.out.println(); System.out.println("extClassloader加载以下文件:"); System.out.println(System.getProperty("java.ext.dirs")); System.out.println(); System.out.println("appClassLoader加载以下文件:"); System.out.println(System.getProperty("java.class.path")); } } 运行结果: null sun.misc.Launcher$ExtClassLoader sun.misc.Launcher$AppClassLoader the bootstrapLoader : null the extClassloader : sun.misc.Launcher$ExtClassLoader@3764951d the appClassLoader : sun.misc.Launcher$AppClassLoader@14dad5dc bootstrapLoader加载以下文件: file:/D:/home/Java/jdk1.8.0_45/jre/lib/resources.jar file:/D:/home/Java/jdk1.8.0_45/jre/lib/rt.jar file:/D:/home/Java/jdk1.8.0_45/jre/lib/sunrsasign.jar file:/D:/home/Java/jdk1.8.0_45/jre/lib/jsse.jar file:/D:/home/Java/jdk1.8.0_45/jre/lib/jce.jar file:/D:/home/Java/jdk1.8.0_45/jre/lib/charsets.jar file:/D:/home/Java/jdk1.8.0_45/jre/lib/jfr.jar file:/D:/home/Java/jdk1.8.0_45/jre/classes extClassloader加载以下文件: D:\home\Java\jdk1.8.0_45\jre\lib\ext;C:\Windows\Sun\Java\lib\ext appClassLoader加载以下文件: D:\home\Java\jdk1.8.0_45\jre\lib\charsets.jar;D:\home\Java\jdk1.8.0_45\jre\lib\deploy.jar;D:\home\Java\jdk1.8.0_45\jre\lib\ext\access-bridge-64.jar;D:\home\Java\jdk1.8.0_45\jre\lib\ext\cldrdata.jar;D:\home\Java\jdk1.8.0_45\jre\lib\ext\dnsns.jar;D:\home\Java\jdk1.8.0_45\jre\lib\ext\jaccess.jar;D:\home\Java\jdk1.8.0_45\jre\lib\ext\jfxrt.jar;D:\home\Java\jdk1.8.0_45\jre\lib\ext\localedata.jar;D:\home\Java\jdk1.8.0_45\jre\lib\ext\nashorn.jar;D:\home\Java\jdk1.8.0_45\jre\lib\ext\sunec.jar;D:\home\Java\jdk1.8.0_45\jre\lib\ext\sunjce_provider.jar;D:\home\Java\jdk1.8.0_45\jre\lib\ext\sunmscapi.jar;D:\home\Java\jdk1.8.0_45\jre\lib\ext\sunpkcs11.jar;D:\home\Java\jdk1.8.0_45\jre\lib\ext\zipfs.jar;D:\home\Java\jdk1.8.0_45\jre\lib\javaws.jar;D:\home\Java\jdk1.8.0_45\jre\lib\jce.jar;D:\home\Java\jdk1.8.0_45\jre\lib\jfr.jar;D:\home\Java\jdk1.8.0_45\jre\lib\jfxswt.jar;D:\home\Java\jdk1.8.0_45\jre\lib\jsse.jar;D:\home\Java\jdk1.8.0_45\jre\lib\management-agent.jar;D:\home\Java\jdk1.8.0_45\jre\lib\plugin.jar;D:\home\Java\jdk1.8.0_45\jre\lib\resources.jar;D:\home\Java\jdk1.8.0_45\jre\lib\rt.jar;D:\Workspace\appom-jvm\target\classes;C:\Users\liulei\.m2\repository\org\apache\zookeeper\zookeeper\3.4.12\zookeeper-3.4.12.jar;C:\Users\liulei\.m2\repository\org\slf4j\slf4j-api\1.7.25\slf4j-api-1.7.25.jar;C:\Users\liulei\.m2\repository\org\slf4j\slf4j-log4j12\1.7.25\slf4j-log4j12-1.7.25.jar;C:\Users\liulei\.m2\repository\log4j\log4j\1.2.17\log4j-1.2.17.jar;C:\Users\liulei\.m2\repository\jline\jline\0.9.94\jline-0.9.94.jar;C:\Users\liulei\.m2\repository\org\apache\yetus\audience-annotations\0.5.0\audience-annotations-0.5.0.jar;C:\Users\liulei\.m2\repository\io\netty\netty\3.10.6.Final\netty-3.10.6.Final.jar;C:\Users\liulei\.m2\repository\com\google\guava\guava\22.0\guava-22.0.jar;C:\Users\liulei\.m2\repository\com\google\code\findbugs\jsr305\1.3.9\jsr305-1.3.9.jar;C:\Users\liulei\.m2\repository\com\google\errorprone\error_prone_annotations\2.0.18\error_prone_annotations-2.0.18.jar;C:\Users\liulei\.m2\repository\com\google\j2objc\j2objc-annotations\1.1\j2objc-annotations-1.1.jar;C:\Users\liulei\.m2\repository\org\codehaus\mojo\animal-sniffer-annotations\1.14\animal-sniffer-annotations-1.14.jar;D:\home\JetBrains\IntelliJ IDEA 2022.1.3\lib\idea_rt.jar类加载器初始化过程:参见类运行加载全过程图可知其中会创建JVM启动器实例sun.misc.Launcher。在Launcher构造方法内部,其创建了两个类加载器,分别是sun.misc.Launcher.ExtClassLoader(扩展类加载器)和sun.misc.Launcher.AppClassLoader(应用类加载器)。JVM默认使用Launcher的getClassLoader()方法返回的类加载器AppClassLoader的实例加载我们的应用程序。//Launcher的构造方法 public Launcher() { Launcher.ExtClassLoader var1; try { // 构造扩展类加载器,在构造的过程中将其父加载器设置为null var1 = Launcher.ExtClassLoader.getExtClassLoader(); } catch (IOException var10) { throw new InternalError("Could not create extension class loader", var10); } try { // 构造应用类加载器,在构造的过程中将其父加载器设置为ExtClassLoader, // Launcher的loader属性值是AppClassLoader,我们一般都是用这个类加载器来加载我们自己写的应用程序 this.loader = Launcher.AppClassLoader.getAppClassLoader(var1); } catch (IOException var9) { throw new InternalError("Could not create application class loader", var9); } Thread.currentThread().setContextClassLoader(this.loader); String var2 = System.getProperty("java.security.manager"); // 省略一些不需关注代码 }双亲委派机制JVM类加载器是有亲子层级结构的,如下图这里类加载其实就有一个双亲委派机制,加载某个类时会先委托父加载器寻找目标类,找不到再委托上层父加载器加载,如果所有父加载器在自己的加载类路径下都找不到目标类,则在自己的类加载路径中查找并载入目标类。比如我们的Math类,最先会找应用程序类加载器加载,应用程序类加载器会先委托扩展类加载器加载,扩展类加载器再委托引导类加载器,顶层引导类加载器在自己的类加载路径里找了半天没找到Math类,则向下退回加载Math类的请求,扩展类加载器收到回复就自己加载,在自己的类加载路径里找了半天也没找到Math类,又向下退回Math类的加载请求给应用程序类加载器,应用程序类加载器于是在自己的类加载路径里找Math类,结果找到了就自己加载了。双亲委派机制说简单点就是,先找父亲加载,不行再由儿子自己加载我们来看下应用程序类加载器AppClassLoader加载类的双亲委派机制源码,AppClassLoader的loadClass方法最终会调用其父类ClassLoader的loadClass方法,该方法的大体逻辑如下:首先,检查一下指定名称的类是否已经加载过,如果加载过了,就不需要再加载,直接返回。如果此类没有加载过,那么,再判断一下是否有父加载器;如果有父加载器,则由父加载器加载(即调用parent.loadClass(name, false);).或者是调用bootstrap类加载器来加载。如果父加载器及bootstrap类加载器都没有找到指定的类,那么调用当前类加载器的findClass方法来完成类加载。//ClassLoader的loadClass方法,里面实现了双亲委派机制 protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { synchronized (getClassLoadingLock(name)) { // 检查当前类加载器是否已经加载了该类 Class<?> c = findLoadedClass(name); if (c == null) { long t0 = System.nanoTime(); try { if (parent != null) { // 如果当前加载器父加载器不为空则委托父加载器加载该类 c = parent.loadClass(name, false); } else { // 如果当前加载器父加载器为空则委托引导类加载器加载该类 c = findBootstrapClassOrNull(name); } } catch (ClassNotFoundException e) { // ClassNotFoundException thrown if class not found // from the non-null parent class loader } if (c == null) { // If still not found, then invoke findClass in order // to find the class. long t1 = System.nanoTime(); // 都会调用URLClassLoader的findClass方法在加载器的类路径里查找并加载该类 c = findClass(name); // this is the defining class loader; record the stats sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0); sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1); sun.misc.PerfCounter.getFindClasses().increment(); } } if (resolve) { // 不会执行 resolveClass(c); } return c; } }为什么要设计双亲委派机制?沙箱安全机制:自己写的java.lang.String.class类不会被加载,这样便可以防止核心API库被随意篡改避免类的重复加载:当父亲已经加载了该类时,就没有必要子ClassLoader再加载一次,保证被加载类的唯一性看一个类加载示例:package java.lang; public class String { public static void main(String[] args) { System.out.println("**************My String Class**************"); } } 运行结果: 错误: 在类 java.lang.String 中找不到 main 方法, 请将 main 方法定义为: public static void main(String[] args) 否则 JavaFX 应用程序类必须扩展javafx.application.Application全盘负责委托机制“全盘负责”是指当一个ClassLoder装载一个类时,除非显示的使用另外一个ClassLoder,该类所依赖及引用的类也由这个ClassLoder载入。自定义类加载器示例:自定义类加载器只需要继承 java.lang.ClassLoader 类,该类有两个核心方法,一个是loadClass(String, boolean),实现了双亲委派机制,还有一个方法是findClass,默认实现是空方法,所以我们自定义类加载器主要是重写findClass方法。public class MyClassLoaderTest { static class MyClassLoader extends ClassLoader { private String classPath; public MyClassLoader(String classPath) { this.classPath = classPath; } private byte[] loadByte(String name) throws Exception { name = name.replaceAll("\\.", "/"); FileInputStream fis = new FileInputStream(classPath + "/" + name + ".class"); int len = fis.available(); byte[] data = new byte[len]; fis.read(data); fis.close(); return data; } protected Class<?> findClass(String name) throws ClassNotFoundException { try { byte[] data = loadByte(name); // defineClass将一个字节数组转为Class对象,这个字节数组是class文件读取后最终的字节数组。 return defineClass(name, data, 0, data.length); } catch (Exception e) { e.printStackTrace(); throw new ClassNotFoundException(); } } } public static void main(String args[]) throws Exception { // 初始化自定义类加载器,会先初始化父类ClassLoader,其中会把自定义类加载器的父加载器设置为应用程序类加载器AppClassLoader MyClassLoader classLoader = new MyClassLoader("D:/Workspace/appom-jvm"); // D盘创建 appom-jvm/com/appom/jvm 几级目录,将User类的复制类User1.class丢入该目录 Class clazz = classLoader.loadClass("com.appom.jvm.User"); Object obj = clazz.newInstance(); Method method = clazz.getDeclaredMethod("sout", null); method.invoke(obj, null); System.out.println(clazz.getClassLoader().getClass().getName()); } } 运行结果: =======自己的加载器加载类调用方法======= com.appom.jvm.MyClassLoaderTest$MyClassLoader打破双亲委派机制再来一个沙箱安全机制示例,尝试打破双亲委派机制,用自定义类加载器加载我们自己实现的 java.lang.String.classpublic class MyClassLoaderTest { static class MyClassLoader extends ClassLoader { private String classPath; public MyClassLoader(String classPath) { this.classPath = classPath; } private byte[] loadByte(String name) throws Exception { name = name.replaceAll("\\.", "/"); FileInputStream fis = new FileInputStream(classPath + "/" + name + ".class"); int len = fis.available(); byte[] data = new byte[len]; fis.read(data); fis.close(); return data; } protected Class<?> findClass(String name) throws ClassNotFoundException { try { byte[] data = loadByte(name); return defineClass(name, data, 0, data.length); } catch (Exception e) { e.printStackTrace(); throw new ClassNotFoundException(); } } /** * 重写类加载方法,实现自己的加载逻辑,不委派给双亲加载 * @param name * @param resolve * @return * @throws ClassNotFoundException */ protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { synchronized (getClassLoadingLock(name)) { // First, check if the class has already been loaded Class<?> c = findLoadedClass(name); if (c == null) { // If still not found, then invoke findClass in order // to find the class. long t1 = System.nanoTime(); c = findClass(name); // this is the defining class loader; record the stats sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1); sun.misc.PerfCounter.getFindClasses().increment(); } if (resolve) { resolveClass(c); } return c; } } } public static void main(String args[]) throws Exception { MyClassLoader classLoader = new MyClassLoader("D:/Workspace/appom-jvm"); //尝试用自己改写类加载机制去加载自己写的java.lang.String.class Class clazz = classLoader.loadClass("java.lang.String"); Object obj = clazz.newInstance(); Method method= clazz.getDeclaredMethod("sout", null); method.invoke(obj, null); System.out.println(clazz.getClassLoader().getClass().getName()); } } 运行结果: java.lang.SecurityException: Prohibited package name: java.lang at java.lang.ClassLoader.preDefineClass(ClassLoader.java:659) at java.lang.ClassLoader.defineClass(ClassLoader.java:758)Tomcat打破双亲委派机制以Tomcat类加载为例,Tomcat 如果使用默认的双亲委派类加载机制行不行?我们思考一下:Tomcat是个web容器, 那么它要解决什么问题:一个web容器可能需要部署两个应用程序,不同的应用程序可能会依赖同一个第三方类库的不同版本,不能要求同一个类库在同一个服务器只有一份,因此要保证每个应用程序的类库都是独立的,保证相互隔离。部署在同一个web容器中相同的类库相同的版本可以共享。否则,如果服务器有10个应用程序,那么要有10份相同的类库加载进虚拟机。web容器也有自己依赖的类库,不能与应用程序的类库混淆。基于安全考虑,应该让容器的类库和程序的类库隔离开来。web容器要支持jsp的修改,我们知道,jsp 文件最终也是要编译成class文件才能在虚拟机中运行,但程序运行后修改jsp已经是司空见惯的事情, web容器需要支持 jsp 修改后不用重启。再看看我们的问题:Tomcat 如果使用默认的双亲委派类加载机制行不行? 答案是不行的。为什么?第一个问题,如果使用默认的类加载器机制,那么是无法加载两个相同类库的不同版本的,默认的类加器是不管你是什么版本的,只在乎你的全限定类名,并且只有一份。第二个问题,默认的类加载器是能够实现的,因为他的职责就是保证唯一性。第三个问题和第一个问题一样。我们再看第四个问题,我们想我们要怎么实现jsp文件的热加载,jsp 文件其实也就是class文件,那么如果修改了,但类名还是一样,类加载器会直接取方法区中已经存在的,修改后的jsp是不会重新加载的。那么怎么办呢?我们可以直接卸载掉这jsp文件的类加载器,所以你应该想到了,每个jsp文件对应一个唯一的类加载器,当一个jsp文件修改了,就直接卸载这个jsp类加载器。重新创建类加载器,重新加载jsp文件。Tomcat自定义加载器详解Tomcat的几个主要类加载器:commonLoader:Tomcat最基本的类加载器,加载路径中的class可以被Tomcat容器本身以及各个Webapp访问;catalinaLoader:Tomcat容器私有的类加载器,加载路径中的class对于Webapp不可见;sharedLoader:各个Webapp共享的类加载器,加载路径中的class对于所有Webapp可见,但是对于Tomcat容器不可见;WebappClassLoader:各个Webapp私有的类加载器,加载路径中的class只对当前Webapp可见,比如加载war包里相关的类,每个war包应用都有自己的WebappClassLoader,实现相互隔离,比如不同war包应用引入了不同的spring版本,这样实现就能加载各自的spring版本;从图中的委派关系中可以看出:CommonClassLoader能加载的类都可以被CatalinaClassLoader和SharedClassLoader使用,从而实现了公有类库的共用,而CatalinaClassLoader和SharedClassLoader自己能加载的类则与对方相互隔离。WebAppClassLoader可以使用SharedClassLoader加载到的类,但各个WebAppClassLoader实例之间相互隔离。而JasperLoader的加载范围仅仅是这个JSP文件所编译出来的那一个.Class文件,它出现的目的就是为了被丢弃:当Web容器检测到JSP文件被修改时,会替换掉目前的JasperLoader的实例,并通过再建立一个新的Jsp类加载器来实现JSP文件的热加载功能。tomcat 这种类加载机制违背了java 推荐的双亲委派模型了吗?答案是:违背了。 很显然,tomcat 不是这样实现,tomcat 为了实现隔离性,没有遵守这个约定,每个webappClassLoader加载自己的目录下的class文件,不会传递给父类加载器,打破了双亲委派机制。模拟实现Tomcat的webappClassLoader加载自己war包应用内不同版本类实现相互共存与隔离public class MyClassLoaderTest { static class MyClassLoader extends ClassLoader { private String classPath; public MyClassLoader(String classPath) { this.classPath = classPath; } private byte[] loadByte(String name) throws Exception { name = name.replaceAll("\\.", "/"); FileInputStream fis = new FileInputStream(classPath + "/" + name + ".class"); int len = fis.available(); byte[] data = new byte[len]; fis.read(data); fis.close(); return data; } protected Class<?> findClass(String name) throws ClassNotFoundException { try { byte[] data = loadByte(name); return defineClass(name, data, 0, data.length); } catch (Exception e) { e.printStackTrace(); throw new ClassNotFoundException(); } } /** * 重写类加载方法,实现自己的加载逻辑,不委派给双亲加载 * @param name * @param resolve * @return * @throws ClassNotFoundException */ protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { synchronized (getClassLoadingLock(name)) { // First, check if the class has already been loaded Class<?> c = findLoadedClass(name); if (c == null) { // If still not found, then invoke findClass in order // to find the class. long t1 = System.nanoTime(); //非自定义的类还是走双亲委派加载 if (!name.startsWith("com.appom.jvm")){ c = this.getParent().loadClass(name); }else{ c = findClass(name); } // this is the defining class loader; record the stats sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1); sun.misc.PerfCounter.getFindClasses().increment(); } if (resolve) { resolveClass(c); } return c; } } } public static void main(String args[]) throws Exception { MyClassLoader classLoader = new MyClassLoader("D:/Workspace/appom-jvm"); Class clazz = classLoader.loadClass("com.appom.jvm.User1"); Object obj = clazz.newInstance(); Method method= clazz.getDeclaredMethod("sout", null); method.invoke(obj, null); System.out.println(clazz.getClassLoader()); System.out.println(); MyClassLoader classLoader = new MyClassLoader("D:/Workspace/appom-jvm1"); Class clazz1 = classLoader1.loadClass("com.appom.jvm.User1"); Object obj1 = clazz1.newInstance(); Method method1= clazz1.getDeclaredMethod("sout", null); method1.invoke(obj1, null); System.out.println(clazz1.getClassLoader()); } } 运行结果: =======自己的加载器加载类调用方法======= com.appom.jvm.MyClassLoaderTest$MyClassLoader@266474c2 =======另外一个User1版本:自己的加载器加载类调用方法======= com.appom.jvm.MyClassLoaderTest$MyClassLoader@66d3c617注意:同一个JVM内,两个相同包名和类名的类对象可以共存,因为他们的类加载器可以不一样,所以看两个类对象是否是同一个,除了看类的包名和类名是否都相同之外,还需要他们的类加载器也是同一个才能认为他们是同一个。模拟实现Tomcat的JasperLoader热加载原理:后台启动线程监听jsp文件变化,如果变化了找到该jsp对应的servlet类的加载器引用(gcroot),重新生成新的JasperLoader加载器赋值给引用,然后加载新的jsp对应的servlet类,之前的那个加载器因为没有gcroot引用了,下一次gc的时候会被销毁。附下User类的代码:package com.appom.jvm; public class User { private int id; private String name; public User() { } public User(int id, String name) { super(); this.id = id; this.name = name; } public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public void sout() { System.out.println("=======自己的加载器加载类调用方法======="); } }

-
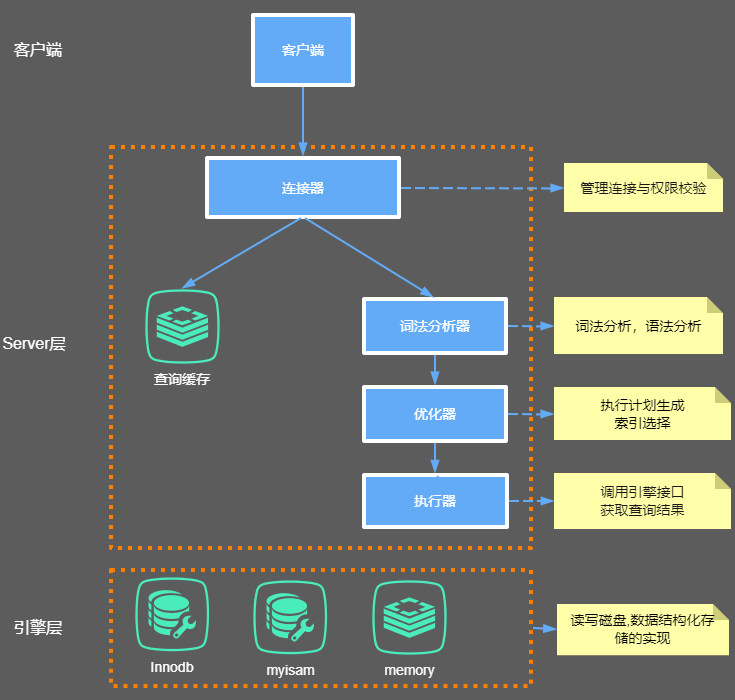
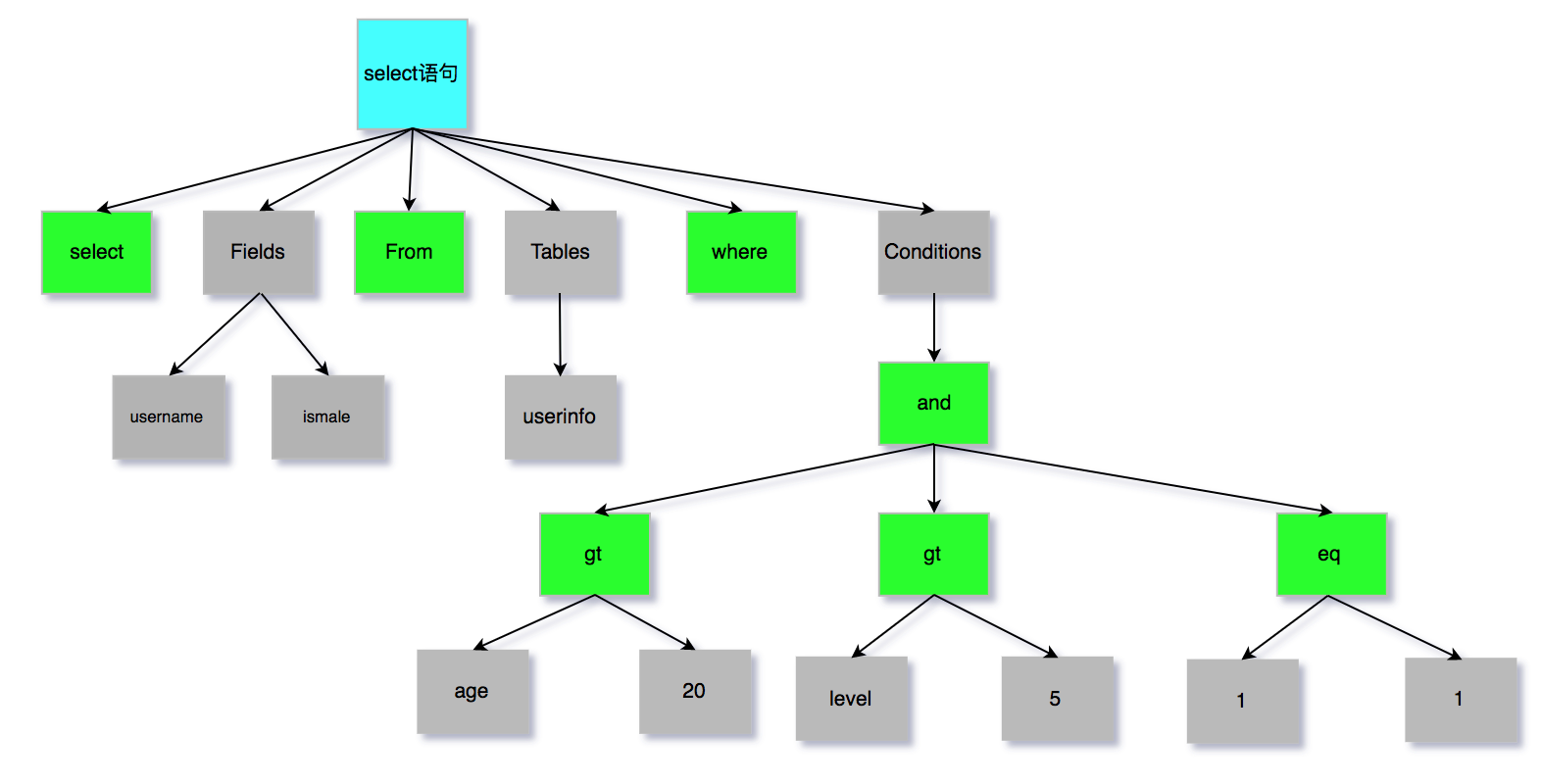
Innodb底层原理与MySQL日志机制 MySQL的内部组件结构大体来说,MySQL 可以分为 Server 层和存储引擎层两部分。Server层主要包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。存储引擎层存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。也就是说如果我们在create table时不指定表的存储引擎类型,默认会给你设置存储引擎为InnoDB。下面我们来看下Server层的连接器、查询缓存、分析器、优化器、执行器分别主要干了哪些事情。连接器我们知道由于MySQL是开源的,他有非常多种类的客户端:navicat,mysql front,jdbc,SQLyog等非常丰富的客户端,包括各种编程语言实现的客户端连接程序,这些客户端要向mysql发起通信都必须先跟Server端建立通信连接,而建立连接的工作就是有连接器完成的。第一步,你会先连接到这个数据库上,这时候接待你的就是连接器。连接器负责跟客户端建立连接、获取权限、维持和管理连接。连接命令一般是这么写的:mysql -h host[数据库地址] -u root[用户] -p root[密码] -P 3306连接命令中的 mysql 是客户端工具,用来跟服务端建立连接。在完成经典的 TCP 握手后,连接器就要开始认证你的身份,这个时候用的就是你输入的用户名和密码。1、如果用户名或密码不对,你就会收到一个"Access denied for user"的错误,然后客户端程序结束执行。2、如果用户名密码认证通过,连接器会到权限表里面查出你拥有的权限。之后,这个连接里面的权限判断逻辑,都将依赖于此时读到的权限。这就意味着,一个用户成功建立连接后,即使你用管理员账号对这个用户的权限做了修改,也不会影响已经存在连接的权限。修改完成后,只有再新建的连接才会使用新的权限设置。查询缓存连接建立完成后,你就可以执行 select 语句了。执行逻辑就会来到第二步:查询缓存。MySQL 拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以 key-value 对的形式,被直接缓存在内存中。key 是查询的语句,value 是查询的结果。如果你的查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。你可以看到,如果查询命中缓存,MySQL 不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高。大多数情况查询缓存就是个鸡肋,为什么呢?因为查询缓存往往弊大于利。查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。因此很可能你费劲地把结果存起来,还没使用呢,就被一个更新全清空了。对于更新压力大的数据库来说,查询缓存的命中率会非常低。一般建议大家在静态表里使用查询缓存,什么叫静态表呢?就是一般我们极少更新的表。比如,一个系统配置表、字典表,那这张表上的查询才适合使用查询缓存。好在 MySQL 也提供了这种“按需使用”的方式。你可以将my.cnf参数 query_cache_type 设置成 DEMAND。my.cnf #query_cache_type有3个值 0代表关闭查询缓存OFF,1代表开启ON,2(DEMAND)代表当sql语句中有SQL_CACHE关键词时才缓存 query_cache_type=2这样对于默认的 SQL 语句都不使用查询缓存。而对于你确定要使用查询缓存的语句,可以用 SQL_CACHE 显式指定,像下面这个语句一样:mysql> select SQL_CACHE * from test where ID=5;查看当前mysql实例是否开启缓存机制mysql> show global variables like "%query_cache_type%";mysql 8.0已经移除了查询缓存功能分析器如果没有命中查询缓存,就要开始真正执行语句了。首先,MySQL 需要知道你要做什么,因此需要对 SQL 语句做解析。分析器先会做“词法分析”。你输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是什么,代表什么。MySQL 从你输入的"select"这个关键字识别出来,这是一个查询语句。它也要把字符串“T”识别成“表名 T”,把字符串“ID”识别成“列 ID”。做完了这些识别以后,就要做“语法分析”。根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。如果你的语句不对,就会收到“You have an error in your SQL syntax”的错误提醒,比如下面这个语句 from 写成了 "rom"。mysql> select * fro test where id=1; ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'fro test where id=1' at line 1下图是分析器对sql的分析过程步骤:SQL语句经过分析器分析之后,会生成一个这样的语法树至此我们分析器的工作任务也基本圆满了。接下来进入到优化器优化器经过了分析器,MySQL 就知道你要做什么了。在开始执行之前,还要先经过优化器的处理。优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序;以及一些mysql自己内部的优化机制。执行器开始执行的时候,要先判断一下你对这个表 T 有没有执行查询的权限,如果没有,就会返回没有权限的错误,如下所示 (在工程实现上,如果命中查询缓存,会在查询缓存返回结果的时候,做权限验证)。mysql> select * from test where id=10;如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。Innodb底层原理与Mysql日志机制redo log重做日志关键参数innodb_log_buffer_size:设置redo log buffer大小参数,默认16M ,最大值是4096M,最小值为1M。show variables like '%innodb_log_buffer_size%';innodb_log_group_home_dir:设置redo log文件存储位置参数,默认值为"./",即innodb数据文件存储位置,其中的 ib_logfile0 和 ib_logfile1 即为redo log文件。show variables like '%innodb_log_group_home_dir%';innodb_log_files_in_group:设置redo log文件的个数,命名方式如: ib_logfile0, iblogfile1... iblogfileN。默认2个,最大100个。show variables like '%innodb_log_files_in_group%';innodb_log_file_size:设置单个redo log文件大小,默认值为48M。最大值为512G,注意最大值指的是整个 redo log系列文件之和,即(innodb_log_files_in_group * innodb_log_file_size)不能大于最大值512G。show variables like '%innodb_log_file_size%';redo log 写入磁盘过程分析:redo log 从头开始写,写完一个文件继续写另一个文件,写到最后一个文件末尾就又回到第一个文件开头循环写,如下面这个图所示。write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头。checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件里。write pos 和 checkpoint 之间的部分就是空着的可写部分,可以用来记录新的操作。如果 write pos 追上checkpoint,表示redo log写满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint 推进一下。innodb_flush_log_at_trx_commit:这个参数控制 redo log 的写入策略,它有三种可能取值:设置为0:表示每次事务提交时都只是把 redo log 留在 redo log buffer 中,数据库宕机可能会丢失数据。设置为1(默认值):表示每次事务提交时都将 redo log 直接持久化到磁盘,数据最安全,不会因为数据库宕机丢失数据,但是效率稍微差一点,线上系统推荐这个设置。设置为2:表示每次事务提交时都只是把 redo log 写到操作系统的缓存page cache里,这种情况如果数据库宕机是不会丢失数据的,但是操作系统如果宕机了,page cache里的数据还没来得及写入磁盘文件的话就会丢失数据。InnoDB 有一个后台线程,每隔 1 秒,就会把 redo log buffer 中的日志,调用 操作系统函数 write 写到文件系统的 page cache,然后调用操作系统函数 fsync 持久化到磁盘文件。 redo log写入策略参看下图:# 查看innodb_flush_log_at_trx_commit参数值: show variables like 'innodb_flush_log_at_trx_commit'; # 设置innodb_flush_log_at_trx_commit参数值(也可以在my.ini或my.cnf文件里配置): set global innodb_flush_log_at_trx_commit=1; binlog二进制归档日志binlog二进制日志记录保存了所有执行过的修改操作语句,不保存查询操作。如果 MySQL 服务意外停止,可通过二进制日志文件排查,用户操作或表结构操作,从而来恢复数据库数据。启动binlog记录功能,会影响服务器性能,但如果需要恢复数据或主从复制功能,则好处则大于对服务器的影响。# 查看binlog相关参数 show variables like '%log_bin%';MySQL5.7 版本中,binlog默认是关闭的,8.0版本默认是打开的。上图中log_bin的值是OFF就代表binlog是关闭状态,打开binlog功能,需要修改配置文件my.ini(windows)或my.cnf(linux),然后重启数据库。在配置文件中的[mysqld]部分增加如下配置:# log-bin设置binlog的存放位置,可以是绝对路径,也可以是相对路径,这里写的相对路径,则binlog文件默认会放在data数据目录下 log-bin=mysql-binlog # Server Id是数据库服务器id,随便写一个数都可以,这个id用来在mysql集群环境中标记唯一mysql服务器,集群环境中每台mysql服务器的id不能一样,不加启动会报错 server-id=1 # 其他配置 binlog_format = row # 日志文件格式,下面会详细解释 expire_logs_days = 15 # 执行自动删除距离当前15天以前的binlog日志文件的天数, 默认为0, 表示不自动删除 max_binlog_size = 200M # 单个binlog日志文件的大小限制,默认为 1GB重启数据库后我们再去看data数据目录会多出两个文件,第一个就是binlog日志文件,第二个是binlog文件的索引文件,这个文件管理了所有的binlog文件的目录。当然也可以执行命令查看有多少binlog文件show binary logs;show variables like '%log_bin%';log_bin:binlog日志是否打开状态log_bin_basename:是binlog日志的基本文件名,后面会追加标识来表示每一个文件,binlog日志文件会滚动增加log_bin_index:指定的是binlog文件的索引文件,这个文件管理了所有的binlog文件的目录。sql_log_bin:sql语句是否写入binlog文件,ON代表需要写入,OFF代表不需要写入。如果想在主库上执行一些操作,但不复制到slave库上,可以通过修改参数sql_log_bin来实现。比如说,模拟主从同步复制异常。binlog 的日志格式用参数 binlog_format 可以设置binlog日志的记录格式,mysql支持三种格式类型:STATEMENT:基于SQL语句的复制,每一条会修改数据的sql都会记录到master机器的bin-log中,这种方式日志量小,节约IO开销,提高性能,但是对于一些执行过程中才能确定结果的函数,比如UUID()、SYSDATE()等函数如果随sql同步到slave机器去执行,则结果跟master机器执行的不一样。ROW:基于行的复制,日志中会记录成每一行数据被修改的形式,然后在slave端再对相同的数据进行修改记录下每一行数据修改的细节,可以解决函数、存储过程等在slave机器的复制问题,但这种方式日志量较大,性能不如Statement。举个例子,假设update语句更新10行数据,Statement方式就记录这条update语句,Row方式会记录被修改的10行数据。MIXED:混合模式复制,实际就是前两种模式的结合,在Mixed模式下,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种,如果sql里有函数或一些在执行时才知道结果的情况,会选择Row,其它情况选择Statement,推荐使用这一种。binlog写入磁盘机制binlog写入磁盘机制主要通过 sync_binlog 参数控制,默认值是 0。为0的时候,表示每次提交事务都只 write 到page cache,由系统自行判断什么时候执行 fsync 写入磁盘。虽然性能得到提升,但是机器宕机,page cache里面的 binlog 会丢失。也可以设置为1,表示每次提交事务都会执行 fsync 写入磁盘,这种方式最安全。还有一种折中方式,可以设置为N(N>1),表示每次提交事务都write 到page cache,但累积N个事务后才 fsync 写入磁盘,这种如果机器宕机会丢失N个事务的binlog。发生以下任何事件时, binlog日志文件会重新生成:服务器启动或重新启动服务器刷新日志,执行命令flush logs日志文件大小达到 max_binlog_size 值,默认值为 1GB删除 binlog 日志文件# 删除当前的binlog文件 reset master; # 删除指定日志文件之前的所有日志文件,下面这个是删除6之前的所有日志文件,当前这个文件不删除 purge master logs to 'mysql-binlog.000006'; # 删除指定日期前的日志索引中binlog日志文件 purge master logs before '2023-01-21 14:00:00';查看 binlog 日志文件可以用mysql自带的命令工具 mysqlbinlog 查看binlog日志内容# 查看bin-log二进制文件(命令行方式,不用登录mysql) mysqlbinlog --no-defaults -v --base64-output=decode-rows D:/home/mysql-5.7.25/data/mysql-binlog.000007 # 查看bin-log二进制文件(带查询条件) mysqlbinlog --no-defaults -v --base64-output=decode-rows D:/home/mysql-5.7.25/data/mysql-binlog.000007 start-datetime="2023-01-21 00:00:00" stop-datetime="2023-02-01 00:00:00" start-position="5000" stop-position="20000"执行mysqlbinlog命令mysqlbinlog --no-defaults -v --base64-output=decode-rows D:/home/mysql-5.7.25/data/mysql-binlog.000007查出来的binlog日志文件内容如下:/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/; /*!50003 SET @OLD_COMPLETION_TYPE=@@COMPLETION_TYPE,COMPLETION_TYPE=0*/; DELIMITER /*!*/; # at 4 #230127 21:13:51 server id 1 end_log_pos 123 CRC32 0x084f390f Start: binlog v 4, server v 5.7.25-log created 230127 21:13:51 at startup # Warning: this binlog is either in use or was not closed properly. ROLLBACK/*!*/; # at 123 #230127 21:13:51 server id 1 end_log_pos 154 CRC32 0x672ba207 Previous-GTIDs # [empty] # at 154 #230127 21:22:48 server id 1 end_log_pos 219 CRC32 0x8349d010 Anonymous_GTID last_committed=0 sequence_number=1 rbr_only=yes /*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/; SET @@SESSION.GTID_NEXT= 'ANONYMOUS'/*!*/; # at 219 #230127 21:22:48 server id 1 end_log_pos 291 CRC32 0xbf49de02 Query thread_id=3 exec_time=0 error_code=0 SET TIMESTAMP=1674825768/*!*/; SET @@session.pseudo_thread_id=3/*!*/; SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/; SET @@session.sql_mode=1342177280/*!*/; SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/; /*!\C utf8 *//*!*/; SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=33/*!*/; SET @@session.lc_time_names=0/*!*/; SET @@session.collation_database=DEFAULT/*!*/; BEGIN /*!*/; # at 291 #230127 21:22:48 server id 1 end_log_pos 345 CRC32 0xc4ab653e Table_map: `test`.`account` mapped to number 99 # at 345 #230127 21:22:48 server id 1 end_log_pos 413 CRC32 0x54a124bd Update_rows: table id 99 flags: STMT_END_F ### UPDATE `test`.`account` ### WHERE ### @1=1 ### @2='lilei' ### @3=1000 ### SET ### @1=1 ### @2='lilei' ### @3=2000 # at 413 #230127 21:22:48 server id 1 end_log_pos 444 CRC32 0x23355595 Xid = 10 COMMIT/*!*/; # at 444 。。。能看到里面有具体执行的修改伪sql语句以及执行时的相关情况。binlog日志文件恢复数据用binlog日志文件恢复数据其实就是回放执行之前记录在binlog文件里的sql,举一个数据恢复的例子# 先执行刷新日志的命令生成一个新的binlog文件mysql-binlog.000008,后面我们的修改操作日志都会记录在最新的这个文件里 flush logs; # 执行两条插入语句 INSERT INTO `test`.`account` (`id`, `name`, `balance`) VALUES ('4', 'zhuge', '666'); INSERT INTO `test`.`account` (`id`, `name`, `balance`) VALUES ('5', 'zhuge1', '888'); # 假设现在误操作执行了一条删除语句把刚新增的两条数据删掉了 DELETE FROM account WHERE id > 3;现在需要恢复被删除的两条数据,我们先查看binlog日志文件mysqlbinlog --no-defaults -v --base64-output=decode-rows D:/home/mysql-5.7.25/data/mysql-binlog.000008文件内容如下:...... SET @@SESSION.GTID_NEXT= 'ANONYMOUS'/*!*/; # at 219 #230127 23:32:24 server id 1 end_log_pos 291 CRC32 0x4528234f Query thread_id=5 exec_time=0 error_code=0 SET TIMESTAMP=1674833544/*!*/; SET @@session.pseudo_thread_id=5/*!*/; SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/; SET @@session.sql_mode=1342177280/*!*/; SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/; /*!\C utf8 *//*!*/; SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=33/*!*/; SET @@session.lc_time_names=0/*!*/; SET @@session.collation_database=DEFAULT/*!*/; BEGIN /*!*/; # at 291 #230127 23:32:24 server id 1 end_log_pos 345 CRC32 0x7482741d Table_map: `test`.`account` mapped to number 99 # at 345 #230127 23:32:24 server id 1 end_log_pos 396 CRC32 0x5e443cf0 Write_rows: table id 99 flags: STMT_END_F ### INSERT INTO `test`.`account` ### SET ### @1=4 ### @2='zhuge' ### @3=666 # at 396 #230127 23:32:24 server id 1 end_log_pos 427 CRC32 0x8a0d8a3c Xid = 56 COMMIT/*!*/; # at 427 #230127 23:32:40 server id 1 end_log_pos 492 CRC32 0x5261a37e Anonymous_GTID last_committed=1 sequence_number=2 rbr_only=yes /*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/; SET @@SESSION.GTID_NEXT= 'ANONYMOUS'/*!*/; # at 492 #230127 23:32:40 server id 1 end_log_pos 564 CRC32 0x01086643 Query thread_id=5 exec_time=0 error_code=0 SET TIMESTAMP=1674833560/*!*/; BEGIN /*!*/; # at 564 #230127 23:32:40 server id 1 end_log_pos 618 CRC32 0xc26b6719 Table_map: `test`.`account` mapped to number 99 # at 618 #230127 23:32:40 server id 1 end_log_pos 670 CRC32 0x8e272176 Write_rows: table id 99 flags: STMT_END_F ### INSERT INTO `test`.`account` ### SET ### @1=5 ### @2='zhuge1' ### @3=888 # at 670 #230127 23:32:40 server id 1 end_log_pos 701 CRC32 0xb5e63d00 Xid = 58 COMMIT/*!*/; # at 701 #230127 23:34:23 server id 1 end_log_pos 766 CRC32 0xa0844501 Anonymous_GTID last_committed=2 sequence_number=3 rbr_only=yes /*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/; SET @@SESSION.GTID_NEXT= 'ANONYMOUS'/*!*/; # at 766 #230127 23:34:23 server id 1 end_log_pos 838 CRC32 0x687bdf88 Query thread_id=7 exec_time=0 error_code=0 SET TIMESTAMP=1674833663/*!*/; BEGIN /*!*/; # at 838 #230127 23:34:23 server id 1 end_log_pos 892 CRC32 0x4f7b7d6a Table_map: `test`.`account` mapped to number 99 # at 892 #230127 23:34:23 server id 1 end_log_pos 960 CRC32 0xc47ac777 Delete_rows: table id 99 flags: STMT_END_F ### DELETE FROM `test`.`account` ### WHERE ### @1=4 ### @2='zhuge' ### @3=666 ### DELETE FROM `test`.`account` ### WHERE ### @1=5 ### @2='zhuge1' ### @3=888 # at 960 #230127 23:34:23 server id 1 end_log_pos 991 CRC32 0x386699fe Xid = 65 COMMIT/*!*/; SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/; DELIMITER ; # End of log file ......找到两条插入数据的sql,每条sql的上下都有BEGIN和COMMIT,我们找到第一条sql BEGIN前面的文件位置标识 at 219(这是文件的位置标识),再找到第二条sql COMMIT后面的文件位置标识 at 701我们可以根据文件位置标识来恢复数据,执行如下sql:mysqlbinlog --no-defaults --start-position=219 --stop-position=701 --database=test D:/home/mysql-5.7.25/data/mysql-binlog.000009 | mysql -uroot -proot -v test # 补充一个根据时间来恢复数据的命令,我们找到第一条sql BEGIN前面的时间戳标记 SET TIMESTAMP=1674833544,再找到第二条sql COMMIT后面的时间戳标记 SET TIMESTAMP=1674833663,转成datetime格式 mysqlbinlog --no-defaults --start-datetime="2023-1-27 23:32:24" --stop-datetime="2023-1-27 23:34:23" --database=test D:/home/mysql-5.7.25/data/mysql-binlog.000009 | mysql -uroot -proot -v test被删除数据被恢复!注意:如果要恢复大量数据,比如程序员经常说的删库跑路的话题,假设我们把数据库所有数据都删除了要怎么恢复了,如果数据库之前没有备份,所有的binlog日志都在的话,就从binlog第一个文件开始逐个恢复每个binlog文件里的数据,这种一般不太可能,因为binlog日志比较大,早期的binlog文件会定期删除的,所以一般不可能用binlog文件恢复整个数据库的。一般我们推荐的是每天(在凌晨后)需要做一次全量数据库备份,那么恢复数据库可以用最近的一次全量备份再加上备份时间点之后的binlog来恢复数据。备份数据库一般可以用mysqldump 命令工具mysqldump -u root 数据库名>备份文件名; #备份整个数据库 mysqldump -u root 数据库名 表名字>备份文件名; #备份整个表 mysql -u root test < 备份文件名 #恢复整个数据库,test为数据库名称,需要自己先建一个数据库test为什么会有redo log和binlog两份日志呢?因为最开始 MySQL 里并没有 InnoDB 引擎。MySQL 自带的引擎是 MyISAM,但是MyISAM 没有 crash-safe 的能力,binlog 日志只能用于归档。而 InnoDB 是另一个公司以插件形式引入 MySQL 的,既然只依靠 binlog 是没有 crash-safe 能力的,所以InnoDB 使用另外一套日志系统——也就是 redo log 来实现 crash-safe 能力。有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe。undo log回滚日志InnoDB对undo log文件的管理采用段的方式,也就是回滚段(rollback segment) 。每个回滚段记录了 1024 个 undo log segment ,每个事务只会使用一个undo log segment。在MySQL5.5的时候,只有一个回滚段,那么最大同时支持的事务数量为1024个。在MySQL 5.6开始,InnoDB支持最大128个回滚段,故其支持同时在线的事务限制提高到了 128*1024 。innodb_undo_directory:设置undo log文件所在的路径。该参数的默认值为"./",即innodb数据文件存储位置,目录下ibdata1文件就是undo log存储的位置。innodb_undo_logs: 设置undo log文件内部回滚段的个数,默认值为128。innodb_undo_tablespaces: 设置undo log文件的数量,这样回滚段可以较为平均地分布在多个文件中。设置该参数后,会在路径innodb_undo_directory看到undo为前缀的文件。undo log日志什么时候删除新增类型的,在事务提交之后就可以清除掉了。修改类型的,事务提交之后不能立即清除掉,这些日志会用于mvcc。只有当没有事务用到该版本信息时才可以清除。为什么Mysql不能直接更新磁盘上的数据而设置这么一套复杂的机制来执行SQL了?因为来一个请求就直接对磁盘文件进行随机读写,然后更新磁盘文件里的数据性能可能相当差。因为磁盘随机读写的性能是非常差的,所以直接更新磁盘文件是不能让数据库抗住很高并发的。Mysql这套机制看起来复杂,但它可以保证每个更新请求都是更新内存BufferPool,然后顺序写日志文件,同时还能保证各种异常情况下的数据一致性。更新内存的性能是极高的,然后顺序写磁盘上的日志文件的性能也是非常高的,要远高于随机读写磁盘文件。正是通过这套机制,才能让我们的MySQL数据库在较高配置的机器上每秒可以抗下几干甚至上万的读写请求。错误日志Mysql还有一个比较重要的日志是错误日志,它记录了数据库启动和停止,以及运行过程中发生任何严重错误时的相关信息。当数据库出现任何故障导致无法正常使用时,建议首先查看此日志。在MySQL数据库中,错误日志功能是默认开启的,而且无法被关闭。# 查看错误日志存放位置 show variables like '%log_error%';通用查询日志通用查询日志记录用户的所有操作,包括启动和关闭MySQL服务、所有用户的连接开始时间和截止时间、发给 MySQL 数据库服务器的所有 SQL 指令等,如select、show等,无论SQL的语法正确还是错误、也无论SQL执行成功还是失败,MySQL都会将其记录下来。通用查询日志用来还原操作时的具体场景,可以帮助我们准确定位一些疑难问题,比如重复支付等问题。general_log:是否开启日志参数,默认为OFF,处于关闭状态,因为开启会消耗系统资源并且占用磁盘空间。一般不建议开启,只在需要调试查询问题时开启。general_log_file:通用查询日志记录的位置参数。show variables like '%general_log%'; # 打开通用查询日志 SET GLOBAL general_log=on;
-
-
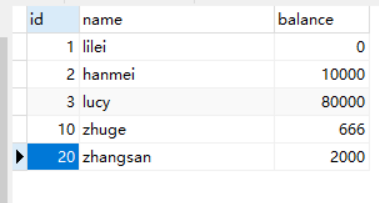
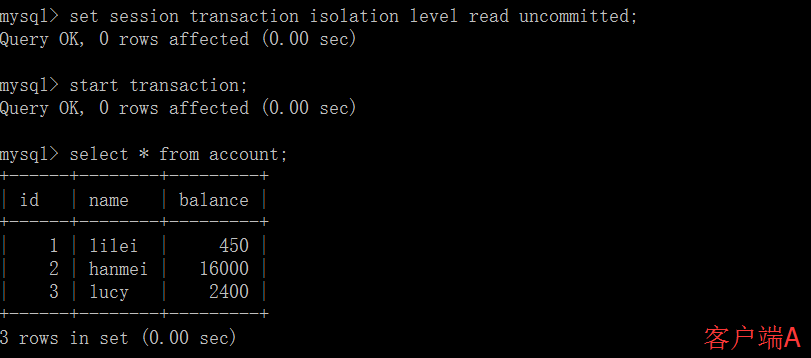
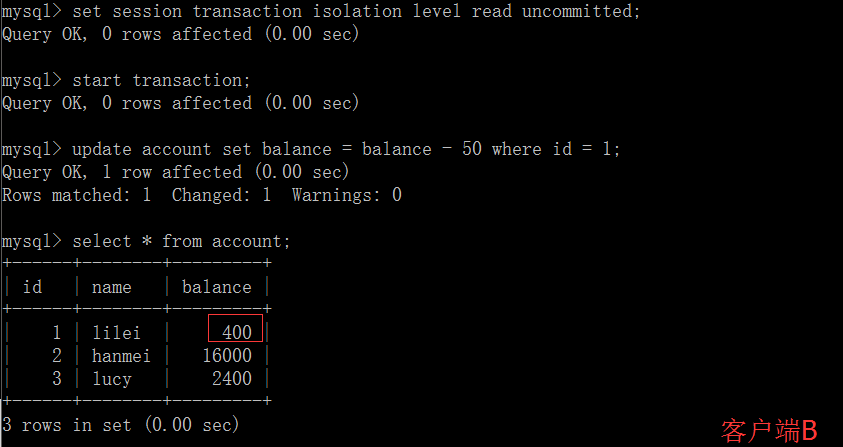
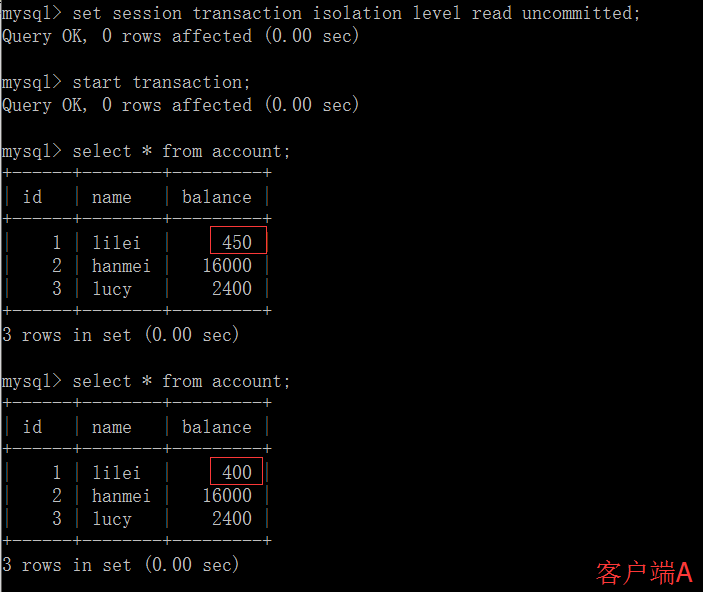
MySQL事务与隔离级别实践 概述我们的数据库一般都会并发执行多个事务,多个事务可能会并发的对相同的一批数据进行增删改查操作,可能就会导致我们说的脏写、脏读、不可重复读、幻读这些问题。这些问题的本质都是数据库的多事务并发问题,为了解决多事务并发问题,数据库设计了事务隔离机制、锁机制、MVCC多版本并发控制隔离机制、日志机制,用一整套机制来解决多事务并发问题。接下来的,我们会深入讲解这些机制,让大家彻底理解数据库内部的执行原理。事务及其ACID属性事务是一组操作要么全部成功,要么全部失败,目的是为了保证数据最终的一致性。事务具有以下4个属性,通常简称为事务的ACID属性。原子性(Atomicity) :当前事务的操作要么同时成功,要么同时失败。原子性由undo log日志来实现。一致性(Consistent) :使用事务的最终目的,由其它3个特性以及业务代码正确逻辑来实现。隔离性(Isolation) :在事务并发执行时,他们内部的操作不能互相干扰。隔离性由MySQL的各种锁以及MVCC机制来实现。持久性(Durable) :一旦提交了事务,它对数据库的改变就应该是永久性的。持久性由redo log日志来实现。并发事务处理带来的问题更新丢失(Lost Update)或脏写:当两个或多个事务选择同一行数据修改,有可能发生更新丢失问题,即最后的更新覆盖了由其他事务所做的更新。脏读(Dirty Reads):事务A读取到了事务B已经修改但尚未提交的数据不可重读(Non-Repeatable Reads) :事务A内部的相同查询语句在不同时刻读出的结果不一致幻读(Phantom Reads):事务A读取到了事务B提交的新增数据事务隔离级别“脏读”、“不可重复读”和“幻读”,其实都是数据库读一致性问题,必须由数据库提供一定的事务隔离机制来解决。隔离级别脏读(Dirty Read)不可重复读(NonRepeatable Read)幻读(Phantom Read)读未提交(Read uncommitted)可能可能可能读已提交(Read committed)不可能可能可能可重复读(Repeatableread)不可能不可能可能可串行化(Serializable)不可能不可能不可能数据库的事务隔离越严格,并发副作用越小,但付出的代价也就越大,因为事务隔离实质上就是使事务在一定程度上“串行化”进行,这显然与“并发”是矛盾的。同时,不同的应用对读一致性和事务隔离程度的要求也是不同的,比如许多应用对“不可重复读"和“幻读”并不敏感,可能更关心数据并发访问的能力。查看当前数据库的事务隔离级别: show variables like 'tx_isolation';设置事务隔离级别:set tx_isolation='REPEATABLE-READ';Mysql默认的事务隔离级别是可重复读,用Spring开发程序时,如果不设置隔离级别默认用Mysql设置的隔离级别,如果Spring设置了就用已经设置的隔离级别事务隔离级别案例分析CREATE TABLE `account` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `balance` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; INSERT INTO `test`.`account` (`name`, `balance`) VALUES ('lilei', '450'); INSERT INTO `test`.`account` (`name`, `balance`) VALUES ('hanmei', '16000'); INSERT INTO `test`.`account` (`name`, `balance`) VALUES ('lucy', '2400');读未提交:(1)打开一个客户端A,并设置当前事务模式为read uncommitted(未提交读),查询表account的初始值:SET tx_isolation='read-uncommitted';(2)在客户端A的事务提交之前,打开另一个客户端B,更新表account:(3)这时,虽然客户端B的事务还没提交,但是客户端A就可以查询到B已经更新的数据: (4)一旦客户端B的事务因为某种原因回滚,所有的操作都将会被撤销,那客户端A查询到的数据其实就是脏数据:5)在客户端A执行更新语句update account set balance = balance - 50 where id =1,lilei的balance没有变成350,居然是400,是不是很奇怪,数据不一致啊,如果你这么想就太天真了,在应用程序中,我们会用400-50=350,并不知道其他会话回滚了,要想解决这个问题可以采用读已提交的隔离级别读已提交:(1)打开一个客户端A,并设置当前事务模式为read committed(未提交读),查询表account的所有记录:SET tx_isolation='read-committed';(2)在客户端A的事务提交之前,打开另一个客户端B,更新表account: (3)这时,客户端B的事务还没提交,客户端A不能查询到B已经更新的数据,解决了脏读问题:(4)客户端B的事务提交(5)客户端A执行与上一步相同的查询,结果 与上一步不一致,即产生了不可重复读的问题可重复读这个隔离级别记住一句话就能理解:可重复读隔离级别在事务开启的时候,第一次查询是查的数据库里已提交的最新数据,这时候全数据库会有一个快照(当然数据库并不是真正的生成了一个快照,这个快照机制怎么实现的后面课程会详细讲),在这个事务之后执行的查询操作都是查快照里的数据,别的事务不管怎么修改数据对当前这个事务的查询都没有影响,但是当前事务如果修改了某条数据,那当前事务之后查这条修改的数据就是被修改之后的值,但是查其它数据依然是从快照里查,不受影响。(1)打开一个客户端A,并设置当前事务模式为repeatable read,查询表account的所有记录SET tx_isolation='repeatable-read';(2)在客户端A的事务提交之前,打开另一个客户端B,更新表account并提交(3)在客户端A查询表account的所有记录,与步骤(1)查询结果一致,没有出现不可重复读的问题(4)在客户端A,接着执行update account set balance = balance - 50 where id = 1,balance没有变成400-50=350,lilei的balance值用的是步骤2中的350来算的,所以是300,数据的一致性倒是没有被破坏。可重复读的隔离级别下使用了MVCC(multi-version concurrency control)机制,select操作是快照读(历史版本);insert、update和delete是当前读(当前版本)。(5)重新打开客户端B,插入一条新数据后提交(6)在客户端A查询表account的所有记录,没有查出新增数据,所以没有出现幻读(7)验证幻读在客户端A执行update account set balance=888 where id = 4;能更新成功,再次查询能查到客户端B新增的数据串行化(1)打开一个客户端A,并设置当前事务模式为serializable,查询表account的初始值:SET tx_isolation='serializable';(2)打开一个客户端B,并设置当前事务模式为serializable,更新相同的id为1的记录会被阻塞等待,更新id为2的记录可以成功,说明在串行模式下innodb的查询也会被加上行锁,如果查询的记录不存在会给这条不存在的记录加上锁(这种是间隙锁,后面会详细讲)。如果客户端A执行的是一个范围查询,那么该范围内的所有行包括每行记录所在的间隙区间范围都会被加锁。此时如果客户端B在该范围内插入数据都会被阻塞,所以就避免了幻读。这种隔离级别并发性极低,开发中很少会用。事务问题定位#查询执行时间超过1秒的事务,详细的定位问题方法后面讲完锁课程后会一起讲解 SELECT * FROM information_schema.innodb_trx WHERE TIME_TO_SEC( timediff( now( ), trx_started ) ) > 1; #强制结束事务 kill 事务对应的线程id(就是上面语句查出结果里的trx_mysql_thread_id字段的值)大事务的影响并发情况下,数据库连接池容易被撑爆锁定太多的数据,造成大量的阻塞和锁超时执行时间长,容易造成主从延迟回滚所需要的时间比较长undo log膨胀容易导致死锁事务优化将查询等数据准备操作放到事务外事务中避免远程调用,远程调用要设置超时,防止事务等待时间太久事务中避免一次性处理太多数据,可以拆分成多个事务分次处理更新等涉及加锁的操作尽可能放在事务靠后的位置能异步处理的尽量异步处理应用侧(业务代码)保证数据一致性,非事务执行你做过的项目或者你们公司使用的什么隔离级别呢?
-
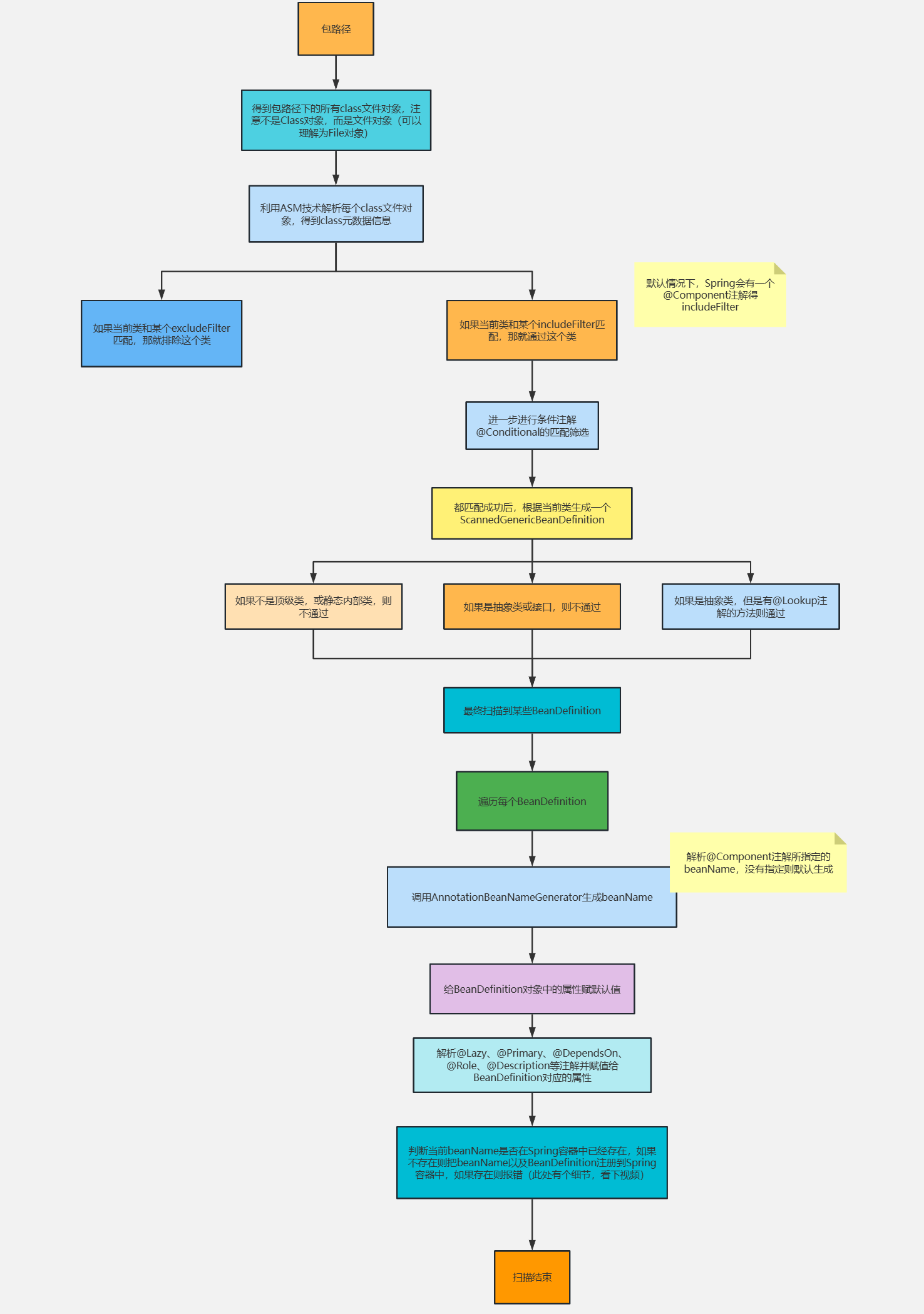
Spring 源码阅读第三节 - Bean的生命周期 Bean的生命周期Bean的生成过程生成BeanDefinition合并BeanDefinition加载类实例化前实例化BeanDefinition的后置处理实例化后自动注入处理属性执行Aware初始化前初始化初始化后Bean的销毁过程Bean的生成过程1. 生成BeanDefinitionSpring启动的时候会进行扫描,会先调用org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#scanCandidateComponents(String basePackage) 扫描某个包路径,并得到BeanDefinition的Set集合。首先,通过ResourcePatternResolver获得指定包路径下的所有 .class 文件(Spring源码中将此文件包装成了Resource对象)遍历每个Resource对象利用MetadataReaderFactory解析Resource对象得到MetadataReader(在Spring源码中MetadataReaderFactory具体的实现类为CachingMetadataReaderFactory,MetadataReader的具体实现类为SimpleMetadataReader)利用MetadataReader进行excludeFilters和includeFilters,以及条件注解@Conditional的筛选(条件注解并不能理解:某个类上是否存在@Conditional注解,如果存在则调用注解中所指定的类的match方法进行匹配,匹配成功则通过筛选,匹配失败则pass掉。)筛选通过后,基于metadataReader生成ScannedGenericBeanDefinition再基于metadataReader判断是不是对应的类是不是接口或抽象类如果筛选通过,那么就表示扫描到了一个Bean,将ScannedGenericBeanDefinition加入结果集MetadataReader表示类的元数据读取器,主要包含了一个AnnotationMetadata,功能有:获取类的名字、获取父类的名字获取所实现的所有接口名获取所有内部类的名字判断是不是抽象类判断是不是接口判断是不是一个注解获取拥有某个注解的方法集合获取类上添加的所有注解信息获取类上添加的所有注解类型集合值得注意的是,CachingMetadataReaderFactory解析某个.class文件得到MetadataReader对象是利用的ASM技术,并没有加载这个类到JVM。并且,最终得到的ScannedGenericBeanDefinition对象,beanClass属性存储的是当前类的名字,而不是class对象。(beanClass属性的类型是Object,它即可以存储类的名字,也可以存储class对象)最后,上面是说的通过扫描得到BeanDefinition对象,我们还可以通过直接定义BeanDefinition,或解析spring.xml文件的<bean/>,或者@Bean注解得到BeanDefinition对象。(后续会分析@Bean注解是怎么生成BeanDefinition的)。2. 合并BeanDefinition通过扫描得到所有BeanDefinition之后,就可以根据BeanDefinition创建Bean对象了,但是在Spring中支持父子BeanDefinition,和Java父子类类似,但是完全不是一回事。父子BeanDefinition实际用的比较少,使用是这样的,比如:<bean id="parent" class="com.demo.service.Parent" scope="prototype"/> <bean id="child" class="com.demo.service.Child"/>这么定义的情况下,child是单例Bean。<bean id="parent" class="com.demo.service.Parent" scope="prototype"/> <bean id="child" class="com.demo.service.Child" parent="parent"/>但是这么定义的情况下,child就是原型Bean了。因为child的父BeanDefinition是parent,所以会继承parent上所定义的scope属性。而在根据child来生成Bean对象之前,需要进行BeanDefinition的合并,得到完整的child的BeanDefinition。3. 加载类BeanDefinition合并之后,就可以去创建Bean对象了,而创建Bean就必须实例化对象,而实例化就必须先加载当前BeanDefinition所对应的class,在AbstractAutowireCapableBeanFactory类的createBean()方法中,一开始就会调用:Class<?> resolvedClass = resolveBeanClass(mbd, beanName);这行代码就是去加载类,该方法是这么实现的:... if (mbd.hasBeanClass()) { return mbd.getBeanClass(); } if (System.getSecurityManager() != null) { return AccessController.doPrivileged((PrivilegedExceptionAction<Class<?>>) () ‐> doResolveBeanClass(mbd, typesToMatch), getAccessControlContext()); } else { return doResolveBeanClass(mbd, typesToMatch); } ...public boolean hasBeanClass() { return (this.beanClass instanceof Class); }如果beanClass属性的类型是Class,那么就直接返回,如果不是,则会根据类名进行加载(doResolveBeanClass方法所做的事情)会利用BeanFactory所设置的类加载器来加载类,如果没有设置,则默认使用ClassUtils.getDefaultClassLoader()所返回的类加载器来加载。ClassUtils.getDefaultClassLoader()优先返回当前线程中的ClassLoader线程中类加载器为null的情况下,返回ClassUtils类的类加载器如果ClassUtils类的类加载器为空,那么则表示是Bootstrap类加载器加载的ClassUtils类,那么则返回系统类加载器4. 实例化前当前BeanDefinition对应的类成功加载后,就可以实例化对象了,但是...在Spring中,实例化对象之前,Spring提供了一个扩展点,允许用户来控制是否在某个或某些Bean实例化之前做一些启动动作。这个扩展点叫InstantiationAwareBeanPostProcessor.postProcessBeforeInstantiation()。比如:@Component public class DemoBeanPostProcessor implements InstantiationAwareBeanPostProcessor { @Override public Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException { if ("userService".equals(beanName)) { System.out.println("实例化前"); } return null; } }如上代码会导致,在userService这个Bean实例化前,会进行打印。值得注意的是,postProcessBeforeInstantiation()是有返回值的,如果这么实现:@Component public class DemoBeanPostProcessor implements InstantiationAwareBeanPostProcessor { @Override public Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException { if ("userService".equals(beanName)) { System.out.println("实例化前"); return new UserService(); } return null; } }5. 实例化在这个步骤中就会根据BeanDefinition去创建一个对象了。5.1 Supplier创建对象首先判断BeanDefinition中是否设置了Supplier,如果设置了则调用Supplier的get()得到对象。得直接使用BeanDefinition对象来设置Supplier,比如:AbstractBeanDefinition beanDefinition = BeanDefinitionBuilder.genericBeanDefinition().getBeanDefinition(); beanDefinition.setInstanceSupplier(new Supplier<Object>() { @Override public Object get() { return new UserService(); } }); context.registerBeanDefinition("userService", beanDefinition);5.2 工厂方法创建对象如果没有设置Supplier,则检查BeanDefinition中是否设置了factoryMethod,也就是工厂方法,有两种方式可以设置factoryMethod,比如:方式一:<bean id="userService" class="com.demo.service.UserService" factory‐ method="createUserService" />对应的UserService类为:public class UserService { public static UserService createUserService() { System.out.println("执行createUserService()"); UserService userService = new UserService(); return userService; } public void test() { System.out.println("test"); } }方式二:<bean id="commonService" class="com.demo.service.CommonService"/> <bean id="userService1" factory‐bean="commonService" factory‐method="createUserService" />对应的CommonService的类为:public class CommonService { public UserService createUserService() { return new UserService(); } }Spring发现当前BeanDefinition方法设置了工厂方法后,就会区分这两种方式,然后调用工厂方法得到对象。值得注意的是,我们通过@Bean所定义的BeanDefinition,是存在factoryMethod和factoryBean的,也就是和上面的方式二非常类似,@Bean所注解的方法就是factoryMethod,AppConfig对象就是factoryBean。如果@Bean所所注解的方法是static的,那么对应的就是方式一。5.3 推断构造方法推断完构造方法后,就会使用构造方法来进行实例化了。额外的,在推断构造方法逻辑中除开会去选择构造方法以及查找入参对象意外,会还判断是否在对应的类中是否存在使用@Lookup注解了方法。如果存在则把该方法封装为LookupOverride对象并添加到BeanDefinition中。在实例化时,如果判断出来当前BeanDefinition中没有LookupOverride,那就直接用构造方法反射得到一个实例对象。如果存在LookupOverride对象,也就是类中存在@Lookup注解了的方法,那就会生成一个代理对象。@Lookup注解就是方法注入,使用demo如下:@Component public class UserService { private OrderService orderService; public void test() { OrderService orderService = createOrderService(); System.out.println(orderService); } @Lookup("orderService") public OrderService createOrderService() { return null; } } 6. BeanDefinition的后置处理Bean对象实例化出来之后,接下来就应该给对象的属性赋值了。在真正给属性赋值之前,Spring又提供了一个扩展点MergedBeanDefinitionPostProcessor.postProcessMergedBeanDefinition(),可以对此时的BeanDefinition进行加工,比如:@Component public class DemoMergedBeanDefinitionPostProcessor implements MergedBeanDefinitionPostProcessor { @Override public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName) { if ("userService".equals(beanName)) { beanDefinition.getPropertyValues().add("orderService", new OrderService()); } } }在Spring源码中,AutowiredAnnotationBeanPostProcessor就是一个MergedBeanDefinitionPostProcessor,它的postProcessMergedBeanDefinition()中会去查找注入点,并缓存在AutowiredAnnotationBeanPostProcessor对象的一个Map中(injectionMetadataCache)。7. 实例化后在处理完BeanDefinition后,Spring又设计了一个扩展点:InstantiationAwareBeanPostProcessor.postProcessAfterInstantiation(),比如:@Component public class DemoInstantiationAwareBeanPostProcessor implements InstantiationAwareBeanPostProcessor { @Override public boolean postProcessAfterInstantiation(Object bean, String beanName) throws BeansException { if ("userService".equals(beanName)) { UserService userService = (UserService) bean; userService.test(); } return true; } }上述代码就是对userService所实例化出来的对象进行处理。这个扩展点,在Spring源码中基本没有怎么使用。8. 自动注入这里的自动注入指的是Spring的自动注入,后续依赖注入单独讲。9. 处理属性这个步骤中,就会处理@Autowired、@Resource、@Value等注解,也是通过InstantiationAwareBeanPostProcessor.postProcessProperties()扩展点来实现的,比如我们甚至可以实现一个自己的自动注入功能,比如:@Component public class DemoInstantiationAwareBeanPostProcessor implements InstantiationAwareBeanPostProcessor { @Override public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) throws BeansException { if ("userService".equals(beanName)) { for (Field field : bean.getClass().getFields()) { if (field.isAnnotationPresent(DemoInject.class)) { field.setAccessible(true); try { field.set(bean, "123"); } catch (IllegalAccessException e) { e.printStackTrace(); } } } } return pvs; } } 关于@Autowired、@Resource、@Value的底层源码,会在后续的依赖注入中详解。10. 执行Aware完成了属性赋值之后,Spring会执行一些回调,包括:BeanNameAware:回传beanName给bean对象。BeanClassLoaderAware:回传classLoader给bean对象。BeanFactoryAware:回传beanFactory给对象。11. 初始化前初始化前,也是Spring提供的一个扩展点:BeanPostProcessor.postProcessBeforeInitialization(),比如:@Component public class DemoBeanPostProcessor implements BeanPostProcessor { @Override public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException { if ("userService".equals(beanName)) { System.out.println("初始化前"); } return bean; } }利用初始化前,可以对进行了依赖注入的Bean进行处理。在Spring源码中:InitDestroyAnnotationBeanPostProcessor会在初始化前这个步骤中执行@PostConstruct的方法,ApplicationContextAwareProcessor会在初始化前这个步骤中进行其他Aware的回调:EnvironmentAware:回传环境变量EmbeddedValueResolverAware:回传占位符解析器ResourceLoaderAware:回传资源加载器ApplicationEventPublisherAware:回传事件发布器MessageSourceAware:回传国际化资源ApplicationStartupAware:回传应用其他监听对象,可忽略ApplicationContextAware:回传Spring容器ApplicationContext12. 初始化查看当前Bean对象是否实现了InitializingBean接口,如果实现了就调用其afterPropertiesSet()方法执行BeanDefinition中指定的初始化方法13. 初始化后这是Bean创建生命周期中的最后一个步骤,也是Spring提供的一个扩展点:BeanPostProcessor.postProcessAfterInitialization(),比如:@Component public class DemoBeanPostProcessor implements BeanPostProcessor { @Override public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException { if ("userService".equals(beanName)) { System.out.println("初始化后"); } return bean; } }可以在这个步骤中,对Bean最终进行处理,Spring中的AOP就是基于初始化后实现的,初始化后返回的对象才是最终的Bean对象。总结BeanPostProcessorInstantiationAwareBeanPostProcessor.postProcessBeforeInstantiation()实例化MergedBeanDefinitionPostProcessor.postProcessMergedBeanDefinition()InstantiationAwareBeanPostProcessor.postProcessAfterInstantiation()自动注入InstantiationAwareBeanPostProcessor.postProcessProperties()Aware对象BeanPostProcessor.postProcessBeforeInitialization()初始化BeanPostProcessor.postProcessAfterInitialization()Bean的销毁过程Bean销毁是发送在Spring容器关闭过程中的。在Spring容器关闭时,比如:AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class); UserService userService = (UserService) context.getBean("userService"); userService.test(); // 容器关闭 context.close();在Bean创建过程中,在最后(初始化之后),有一个步骤会去判断当前创建的Bean是不是DisposableBean:当前Bean是否实现了DisposableBean接口或者,当前Bean是否实现了AutoCloseable接口BeanDefinition中是否指定了destroyMethod调用DestructionAwareBeanPostProcessor.requiresDestruction(bean)进行判断ApplicationListenerDetector中直接使得ApplicationListener是DisposableBeanInitDestroyAnnotationBeanPostProcessor中使得拥有@PreDestroy注解了的方法就是DisposableBean把符合上述任意一个条件的Bean适配成DisposableBeanAdapter对象,并存入disposableBeans中(一个LinkedHashMap)在Spring容器关闭过程时:首先发布ContextClosedEvent事件调用lifecycleProcessor的onCloese()方法销毁单例Bean遍历disposableBeans把每个disposableBean从单例池中移除调用disposableBean的destroy()如果这个disposableBean还被其他Bean依赖了,那么也得销毁其他Bean如果这个disposableBean还包含了inner beans,将这些Bean从单例池中移除掉(inner bean参考https://docs.spring.io/spring-framework/docs/current/spring-framework-reference/core.html#beans-inner-beans)清空manualSingletonNames,是一个Set,存的是用户手动注册的单例Bean的beanName清空allBeanNamesByType,是一个Map,key是bean类型,value是该类型所有的beanName数组清空singletonBeanNamesByType,和allBeanNamesByType类似,只不过只存了单例Bean这里涉及到一个设计模式:适配器模式在销毁时,Spring会找出实现了DisposableBean接口的Bean。但是我们在定义一个Bean时,如果这个Bean实现了DisposableBean接口,或者实现了AutoCloseable接口,或者在BeanDefinition中指定了destroyMethodName,那么这个Bean都属于“DisposableBean”,这些Bean在容器关闭时都要调用相应的销毁方法。所以,这里就需要进行适配,将实现了DisposableBean接口、或者AutoCloseable接口等适配成实现了DisposableBean接口,所以就用到了DisposableBeanAdapter。会把实现了AutoCloseable接口的类封装成DisposableBeanAdapter,而DisposableBeanAdapter实现了DisposableBean接口。
-
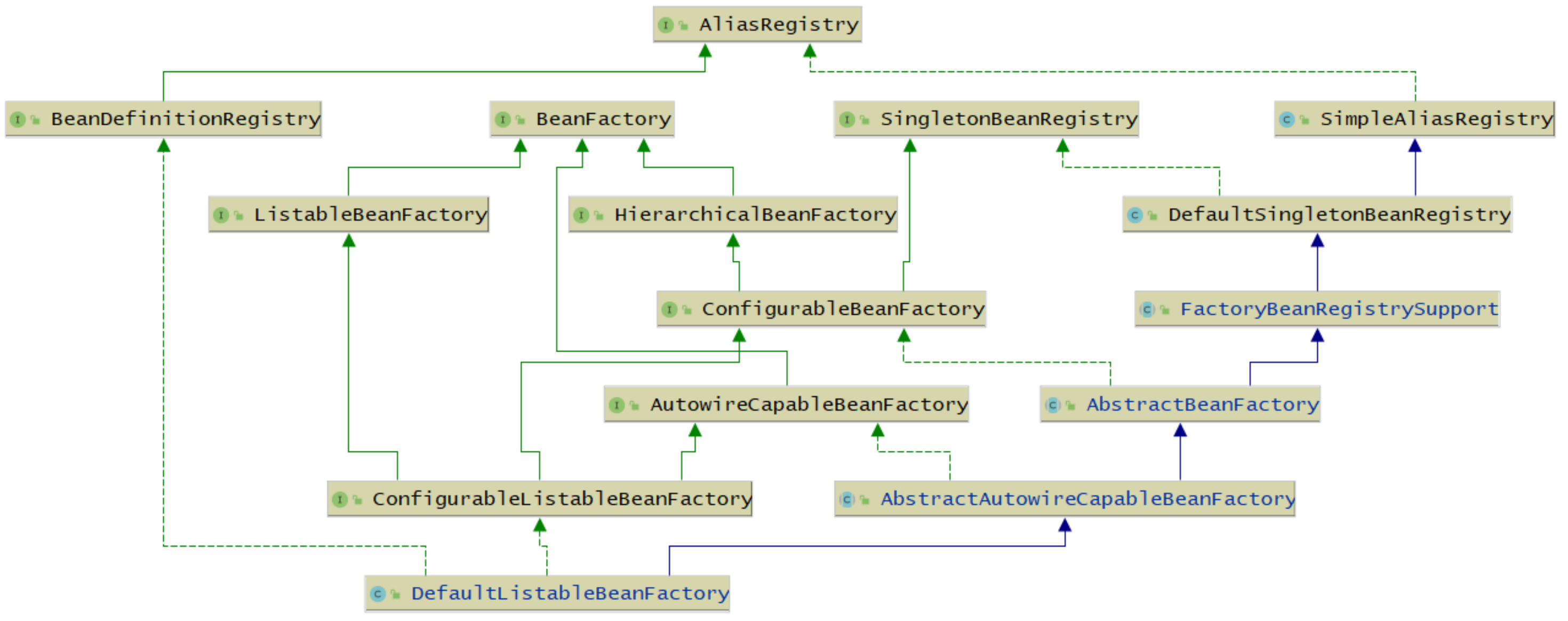
Spring 源码阅读第二节 - 关键概念 Spring底层架构核心概念BeanDefinitionBeanDefinitionReaderClassPathBeanDefinitionScannerBeanFactoryApplicationContextAnnotationConfigApplicationContextClassPathXmlApplicationContextBeanPostProcessorBeanFactoryPostProcessorFactoryBeanExcludeFilter和IncludeFilterMetadataReader、ClassMetadata、AnnotationMetadataBeanDefinitionBeanDefinition表示Bean定义,BeanDefinition中存在很多属性用来描述一个Bean的特点。比如:class,表示Bean类型scope,表示Bean作用域,单例或原型等lazyInit:表示Bean是否是懒加载initMethodName:表示Bean初始化时要执行的方法destroyMethodName:表示Bean销毁时要执行的方法还有很多...在Spring中,我们经常会通过以下几种方式来定义Bean:<bean/>@Bean@Component(@Service,@Controller)这些,我们可以称之申明式定义Bean。我们还可以编程式定义Bean,那就是直接通过BeanDefinition,比如:AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class); // 生成一个BeanDefinition对象,并设置beanClass为User.class,并注册到ApplicationContext中 AbstractBeanDefinition beanDefinition = BeanDefinitionBuilder.genericBeanDefinition().getBeanDefinition(); beanDefinition.setBeanClass(User.class); context.registerBeanDefinition("user", beanDefinition); System.out.println(context.getBean("user"));我们还可以通过BeanDefinition设置一个Bean的其他属性和申明式事务、编程式事务类似,通过<bean/>,@Bean,@Component等申明式方式所定义的Bean,最终都会被Spring解析为对应的BeanDefinition对象,并放入Spring容器中。beanDefinition.setScope("prototype"); // 设置作用域 beanDefinition.setInitMethodName("init"); // 设置初始化方法 beanDefinition.setLazyInit(true); // 设置懒加载BeanDefinitionReader种在Spring源码中所提供的BeanDefinition读取器(BeanDefinitionReader),这些BeanDefinitionReader在我们使用Spring时用得少,但在Spring源码中用得多,相当于Spring源码的基础设施。AnnotatedBeanDefinitionReader可以直接把某个类转换为BeanDefinition,并且会解析该类上的注解,比如AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class); AnnotatedBeanDefinitionReader annotatedBeanDefinitionReader = new AnnotatedBeanDefinitionReader(context); // 将User.class解析为BeanDefinition annotatedBeanDefinitionReader.register(User.class); System.out.println(context.getBean("user"));注意:它能解析的注解是:@Conditional,@Scope、@Lazy、@Primary、@DependsOn、@Role、@DescriptionXmlBeanDefinitionReader可以解析<bean/>标签AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class); XmlBeanDefinitionReader xmlBeanDefinitionReader = new XmlBeanDefinitionReader(context); int i = xmlBeanDefinitionReader.loadBeanDefinitions("spring.xml"); System.out.println(context.getBean("user"));ClassPathBeanDefinitionScannerClassPathBeanDefinitionScanner是扫描器,但是它的作用和BeanDefinitionReader类似,它可以进行扫描,扫描某个包路径,对扫描到的类进行解析,比如,扫描到的类上如果存在@Component注解,那么就会把这个类解析为一个BeanDefinition,比如:AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(); context.refresh(); ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(context); scanner.scan("com.demo"); System.out.println(context.getBean("userService"));BeanFactoryBeanFactory表示Bean工厂,所以很明显,BeanFactory会负责创建Bean,并且提供获取Bean的API。而ApplicationContext是BeanFactory的一种,在Spring源码中,是这么定义的:public interface ApplicationContext extends EnvironmentCapable, ListableBeanFactory, HierarchicalBeanFactory, MessageSource, ApplicationEventPublisher, ResourcePatternResolver { ... }首先,在Java中,接口是可以多继承的,我们发现ApplicationContext继承了ListableBeanFactory和HierarchicalBeanFactory,而ListableBeanFactory和HierarchicalBeanFactory都继承至BeanFactory,所以我们可以认为ApplicationContext继承了BeanFactory,相当于苹果继承水果,宝马继承汽车一样,ApplicationContext也是BeanFactory的一种,拥有BeanFactory支持的所有功能,不过ApplicationContext比BeanFactory更加强大,ApplicationContext还基础了其他接口,也就表示ApplicationContext还拥有其他功能,比如MessageSource表示国际化,ApplicationEventPublisher表示事件发布,EnvironmentCapable表示获取环境变量,等等,关于ApplicationContext后面再详细讨论。在Spring的源码实现中,当我们new一个ApplicationContext时,其底层会new一个BeanFactory出来,当使用ApplicationContext的某些方法时,比如getBean(),底层调用的是BeanFactory的getBean()方法。在Spring源码中,BeanFactory接口存在一个非常重要的实现类是:DefaultListableBeanFactory也是非常核心的。具体重要性,随着阅读后续会感受更深。所以,我们可以直接来使用DefaultListableBeanFactory,而不用使用ApplicationContext的某个实现类,比如:DefaultListableBeanFactory beanFactory = new DefaultListableBeanFactory(); AbstractBeanDefinition beanDefinition = BeanDefinitionBuilder.genericBeanDefinition().getBeanDefinition(); beanDefinition.setBeanClass(User.class); beanFactory.registerBeanDefinition("user", beanDefinition); System.out.println(beanFactory.getBean("user"));DefaultListableBeanFactory是非常强大的,支持很多功能,可以通过查看DefaultListableBeanFactory的类继承实现结构来看它实现了很多接口,表示,它拥有很多功能:AliasRegistry:支持别名功能,一个名字可以对应多个别名BeanDefinitionRegistry:可以注册、保存、移除、获取某个BeanDefinitionBeanFactory:Bean工厂,可以根据某个bean的名字、或类型、或别名获取某个Bean对象SingletonBeanRegistry:可以直接注册、获取某个单例BeanSimpleAliasRegistry:它是一个类,实现了AliasRegistry接口中所定义的功能,支持别名功能ListableBeanFactory:在BeanFactory的基础上,增加了其他功能,可以获取所有BeanDefinition的beanNames,可以根据某个类型获取对应的beanNames,可以根据某个类型获取{类型:对应的Bean}的映射关系HierarchicalBeanFactory:在BeanFactory的基础上,添加了获取父BeanFactory的功能DefaultSingletonBeanRegistry:它是一个类,实现了SingletonBeanRegistry接口,拥有了直接注册、获取某个单例Bean的功能ConfigurableBeanFactory:在HierarchicalBeanFactory和SingletonBeanRegistry的基础上,添加了设置父BeanFactory、类加载器(表示可以指定某个类加载器进行类的加载)、设置Spring EL表达式解析器(表示该BeanFactory可以解析EL表达式)、设置类型转化服务(表示该BeanFactory可以进行类型转化)、可以添加BeanPostProcessor(表示该BeanFactory支持Bean的后置处理器),可以合并BeanDefinition,可以销毁某个Bean等等功能FactoryBeanRegistrySupport:支持了FactoryBean的功能AutowireCapableBeanFactory:是直接继承了BeanFactory,在BeanFactory的基础上,支持在创建Bean的过程中能对Bean进行自动装配AbstractBeanFactory:实现了ConfigurableBeanFactory接口,继承了FactoryBeanRegistrySupport,这个BeanFactory的功能已经很全面了,但是不能自动装配和获取beanNamesConfigurableListableBeanFactory:继承了ListableBeanFactory、AutowireCapableBeanFactory、ConfigurableBeanFactoryAbstractAutowireCapableBeanFactory:继承了AbstractBeanFactory,实现了AutowireCapableBeanFactory,拥有了自动装配的功能DefaultListableBeanFactory:继承了AbstractAutowireCapableBeanFactory,实现了ConfigurableListableBeanFactory接口和BeanDefinitionRegistry接口,所以DefaultListableBeanFactory的功能很强大ApplicationContext上面有分析到,ApplicationContext是个接口,实际上也是一个BeanFactory,不过比BeanFactory更加强大,比如:HierarchicalBeanFactory:拥有获取父BeanFactory的功能ListableBeanFactory:拥有获取beanNames的功能ResourcePatternResolver:资源加载器,可以一次性获取多个资源(文件资源等等)EnvironmentCapable:可以获取运行时环境(没有设置运行时环境功能)ApplicationEventPublisher:拥有广播事件的功能(没有添加事件监听器的功能)MessageSource:拥有国际化功能我们先来看ApplicationContext两个比较重要的实现类:AnnotationConfigApplicationContextClassPathXmlApplicationContextAnnotationConfigApplicationContextConfigurableApplicationContext:继承了ApplicationContext接口,增加了,添加事件监听器、添加BeanFactoryPostProcessor、设置Environment,获取ConfigurableListableBeanFactory等功能AbstractApplicationContext:实现了ConfigurableApplicationContext接口GenericApplicationContext:继承了AbstractApplicationContext,实现了BeanDefinitionRegistry接口,拥有了所有ApplicationContext的功能,并且可以注册BeanDefinition,注意这个类中有一个属性(DefaultListableBeanFactory beanFactory)AnnotationConfigRegistry:可以单独注册某个为类为BeanDefinition(可以处理该类上的@Configuration注解,已经可以处理@Bean注解),同时可以扫描AnnotationConfigApplicationContext:继承了GenericApplicationContext,实现了AnnotationConfigRegistry接口,拥有了以上所有的功能ClassPathXmlApplicationContext它也是继承了AbstractApplicationContext,但是相对于AnnotationConfigApplicationContext而言,功能没有AnnotationConfigApplicationContext强大,比如不能注册BeanDefinition国际化先定义一个MessageSource:@Bean public MessageSource messageSource() { ResourceBundleMessageSource messageSource = new ResourceBundleMessageSource(); messageSource.setBasename("messages"); return messageSource; }有了这个Bean,你可以在你任意想要进行国际化的地方使用该MessageSource。 同时,因为ApplicationContext也拥有国家化的功能,所以可以直接这么用:context.getMessage("test", null, new Locale("en_CN"))资源加载ApplicationContext还拥有资源加载的功能,比如,可以直接利用ApplicationContext获取某个文件的内容:AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class); Resource resource = context.getResource("file://D:\\Workspaces\\spring‐ framework\\demo\\src\\main\\java\\com\\demo\\entity\\User.java"); System.out.println(resource.contentLength());如果你不使用ApplicationContext,而是自己来实现这个功能,就比较费时间了。还比如你可以:AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class); Resource resource = context.getResource("file://D:\\Workspaces\\spring‐ framework\\demo\\src\\main\\java\\com\\demo\\service\\UserService.java"); System.out.println(resource.contentLength()); System.out.println(resource.getFilename()); Resource resource1 = context.getResource("https://www.appom.cn"); System.out.println(resource1.contentLength()); System.out.println(resource1.getURL()); Resource resource2 = context.getResource("classpath:spring.xml"); System.out.println(resource2.contentLength()); System.out.println(resource2.getURL()); 还可以一次性获取多个:Resource[] resources = context.getResources("classpath:com/demo/*.class"); for (Resource resource : resources) { System.out.println(resource.contentLength()); System.out.println(resource.getFilename()); }获取运行时环境AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class); Map<String, Object> systemEnvironment = context.getEnvironment().getSystemEnvironment(); System.out.println(systemEnvironment); System.out.println("======="); Map<String, Object> systemProperties = context.getEnvironment().getSystemProperties(); System.out.println(systemProperties); System.out.println("======="); MutablePropertySources propertySources = context.getEnvironment().getPropertySources(); System.out.println(propertySources); System.out.println("======="); System.out.println(context.getEnvironment().getProperty("VERSION")); System.out.println(context.getEnvironment().getProperty("sun.jnu.encoding")); System.out.println(context.getEnvironment().getProperty("netty"));* 可以利用@PropertySource("classpath:spring.properties")来使得某个properties文件中的参数添加到运行时环境中事件发布先定义一个事件监听器@Bean public ApplicationListener applicationListener() { return new ApplicationListener() { @Override public void onApplicationEvent(ApplicationEvent event) { System.out.println("接收到了一个事件"); } }; }然后发布事件:context.publishEvent("appom");类型转化在Spring源码中,有可能需要把String转成其他类型,所以在Spring源码中提供了一些技术来更方便的做对象的类型转化,关于类型转化的应用场景, 后续看源码的过程中会遇到很多。PropertyEditor这其实是JDK中提供的类型转化工具类public class StringToUserPropertyEditor extends PropertyEditorSupport implements PropertyEditor { @Override public void setAsText(String text) throws IllegalArgumentException { User user = new User(); user.setName(text); this.setValue(user); } }StringToUserPropertyEditor propertyEditor = new StringToUserPropertyEditor(); propertyEditor.setAsText("1"); User value = (User) propertyEditor.getValue(); System.out.println(value);如何向Spring中注册PropertyEditor:@Bean public CustomEditorConfigurer customEditorConfigurer() { CustomEditorConfigurer customEditorConfigurer = new CustomEditorConfigurer(); Map<Class<?>, Class<? extends PropertyEditor>> propertyEditorMap = new HashMap<>(); // 表示StringToUserPropertyEditor可以将String转化成User类型,在Spring源码中,如果发现当前 对象是String,而需要的类型是User,就会使用该PropertyEditor来做类型转化 propertyEditorMap.put(User.class, StringToUserPropertyEditor.class); customEditorConfigurer.setCustomEditors(propertyEditorMap); return customEditorConfigurer; }假设现在有如下Bean:@Component public class UserService { @Value("appom") private User user; public void test() { System.out.println(user); } }那么test属性就能正常的完成属性赋值ConversionServiceSpring中提供的类型转化服务,它比PropertyEditor更强大public class StringToUserConverter implements ConditionalGenericConverter { @Override public boolean matches(TypeDescriptor sourceType, TypeDescriptor targetType) { return sourceType.getType().equals(String.class) && targetType.getType().equals(User.class); } @Override public Set<ConvertiblePair> getConvertibleTypes() { return Collections.singleton(new ConvertiblePair(String.class, User.class)); } @Override public Object convert(Object source, TypeDescriptor sourceType, TypeDescriptor targetType) { User user = new User(); user.setName((String)source); return user; } }DefaultConversionService conversionService = new DefaultConversionService(); conversionService.addConverter(new StringToUserConverter()); User value = conversionService.convert("1", User.class); System.out.println(value);如何向Spring中注册ConversionService:@Bean public ConversionServiceFactoryBean conversionService() { ConversionServiceFactoryBean conversionServiceFactoryBean = new ConversionServiceFactoryBean(); conversionServiceFactoryBean.setConverters(Collections.singleton(new StringToUserConverter())); return conversionServiceFactoryBean; }TypeConverter整合了PropertyEditor和ConversionService的功能,是Spring内部用的SimpleTypeConverter typeConverter = new SimpleTypeConverter(); typeConverter.registerCustomEditor(User.class, new StringToUserPropertyEditor()); //typeConverter.setConversionService(conversionService); User value = typeConverter.convertIfNecessary("1", User.class); System.out.println(value);OrderComparatorOrderComparator是Spring所提供的一种比较器,可以用来根据@Order注解或实现Ordered接口来执行值进行笔记,从而可以进行排序。比如:public class A implements Ordered { @Override public int getOrder() { return 3; } @Override public String toString() { return this.getClass().getSimpleName(); } } public class B implements Ordered { @Override public int getOrder() { return 2; } @Override public String toString() { return this.getClass().getSimpleName(); } } public class Main { public static void main(String[] args) { A a = new A(); // order=3 B b = new B(); // order=2 OrderComparator comparator = new OrderComparator(); System.out.println(comparator.compare(a, b)); // 1 List list = new ArrayList<>(); list.add(a); list.add(b); // 按order值升序排序 list.sort(comparator); System.out.println(list); // B,A } }另外,Spring中还提供了一个OrderComparator的子类:AnnotationAwareOrderComparator,它支持用@Order来指定order值。比如:@Order(3) public class A { @Override public String toString() { return this.getClass().getSimpleName(); } } @Order(2) public class B { @Override public String toString() { return this.getClass().getSimpleName(); } } public class Main { public static void main(String[] args) { A a = new A(); // order=3 B b = new B(); // order=2 AnnotationAwareOrderComparator comparator = new AnnotationAwareOrderComparator(); System.out.println(comparator.compare(a, b)); // 1 List list = new ArrayList<>(); list.add(a); list.add(b); // 按order值升序排序 list.sort(comparator); System.out.println(list); // B,A } }BeanPostProcessorBeanPostProcess表示Bena的后置处理器,我们可以定义一个或多个BeanPostProcessor,比如通过一下代码定义一个BeanPostProcessor:@Component public class DemoBeanPostProcessor implements BeanPostProcessor { @Override public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException { if ("userService".equals(beanName)) { System.out.println("初始化前"); } return bean; } @Override public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException { if ("userService".equals(beanName)) { System.out.println("初始化后"); } return bean; } } 一个BeanPostProcessor可以在任意一个Bean的初始化之前以及初始化之后去额外的做一些用户自定义的逻辑,当然,我们可以通过判断beanName来进行针对性处理(针对某个Bean,或某部分Bean)。我们可以通过定义BeanPostProcessor来干涉Spring创建Bean的过程。BeanFactoryPostProcessorBeanFactoryPostProcessor表示Bean工厂的后置处理器,其实和BeanPostProcessor类似,BeanPostProcessor是干涉Bean的创建过程,BeanFactoryPostProcessor是干涉BeanFactory的创建过程。比如,我们可以这样定义一个BeanFactoryPostProcessor:@Component public class DemoBeanFactoryPostProcessor implements BeanFactoryPostProcessor { @Override public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException { System.out.println("加工beanFactory"); } }我们可以在postProcessBeanFactory()方法中对BeanFactory进行加工。FactoryBean我们可以通过BeanPostPorcessor来干涉Spring创建Bean的过程,但是如果我们想一个Bean完完全全由我们来创造,也是可以的,比如通过FactoryBean:@Component public class DemoFactoryBean implements FactoryBean { @Override public Object getObject() throws Exception { UserService userService = new UserService(); return userService; } @Override public Class<?> getObjectType() { return UserService.class; } }通过上面这段代码,我们自己创造了一个UserService对象,并且它将成为Bean。但是通过这种方式创造出来的UserService的Bean,只会经过初始化后,其他Spring的生命周期步骤是不会经过的,比如依赖注入。学者可能会想到,通过@Bean也可以自己生成一个对象作为Bean,那么和FactoryBean的区别是什么呢?其实在很多场景下他俩是可以替换的,但是站在原理层面来说的,区别很明显,@Bean定义的Bean是会经过完整的Bean生命周期的。ExcludeFilter和IncludeFilter这两个Filter是Spring扫描过程中用来过滤的。ExcludeFilter表示排除过滤器,IncludeFilter表示包含过滤器。比如以下配置,表示扫描com.demo这个包下面的所有类,但是排除UserService类,也就是就算它上面有@Component注解也不会成为Bean。@ComponentScan(value = "com.demo", excludeFilters = {@ComponentScan.Filter( type = FilterType.ASSIGNABLE_TYPE, classes = UserService.class)}.) public class AppConfig { }再比如以下配置,就算UserService类上没有@Component注解,它也会被扫描成为一个Bean。@ComponentScan(value = "com.demo", includeFilters = {@ComponentScan.Filter( type = FilterType.ASSIGNABLE_TYPE, classes = UserService.class)}) public class AppConfig { }FilterType分为:ANNOTATION:表示是否包含某个注解ASSIGNABLE_TYPE:表示是否是某个类ASPECTJ:表示否是符合某个Aspectj表达式REGEX:表示是否符合某个正则表达式CUSTOM:自定义在Spring的扫描逻辑中,默认会添加一个AnnotationTypeFilter给includeFilters,表示默认情况下Spring扫描过程中会认为类上有@Component注解的就是Bean。MetadataReader、ClassMetadata、AnnotationMetadata在Spring中需要去解析类的信息,比如类名、类中的方法、类上的注解,这些都可以称之为类的元数据,所以Spring中对类的元数据做了抽象,并提供了一些工具类。MetadataReader表示类的元数据读取器,默认实现类为SimpleMetadataReader。比如:public class Test { public static void main(String[] args) throws IOException { SimpleMetadataReaderFactory simpleMetadataReaderFactory = new SimpleMetadataReaderFactory(); // 构造一个MetadataReader MetadataReader metadataReader = simpleMetadataReaderFactory.getMetadataReader("com.demo.service.UserService"); // 得到一个ClassMetadata,并获取了类名 ClassMetadata classMetadata = metadataReader.getClassMetadata(); System.out.println(classMetadata.getClassName()); // 获取一个AnnotationMetadata,并获取类上的注解信息 AnnotationMetadata annotationMetadata = metadataReader.getAnnotationMetadata(); for (String annotationType : annotationMetadata.getAnnotationTypes()) { System.out.println(annotationType); } } }需要注意的是,SimpleMetadataReader去解析类时,使用的ASM技术。为什么要使用ASM技术,Spring启动的时候需要去扫描,如果指定的包路径比较宽泛,那么扫描的类是非常多的,那如果在Spring启动时就把这些类全部加载进JVM了,这样不太好,所以使用了ASM技术。