搜索到
42
篇与
资料整理
的结果
-
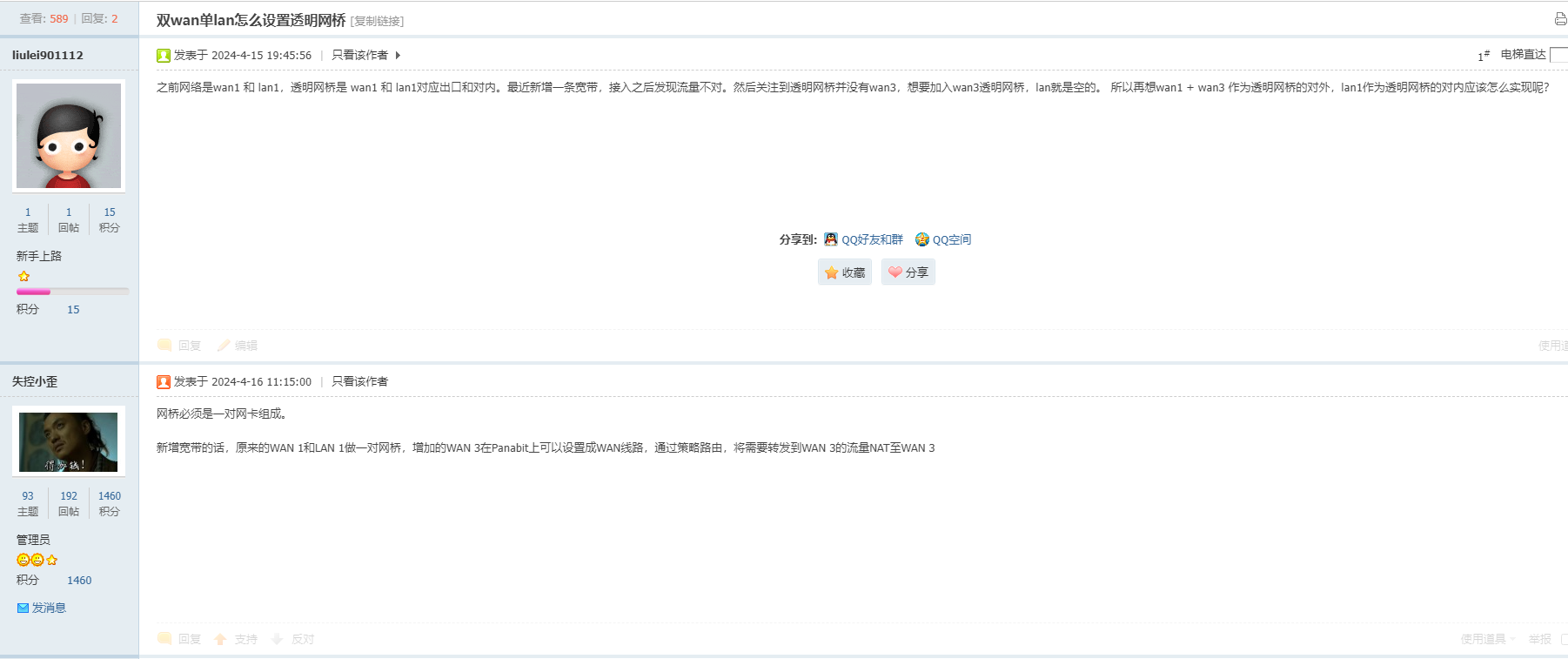
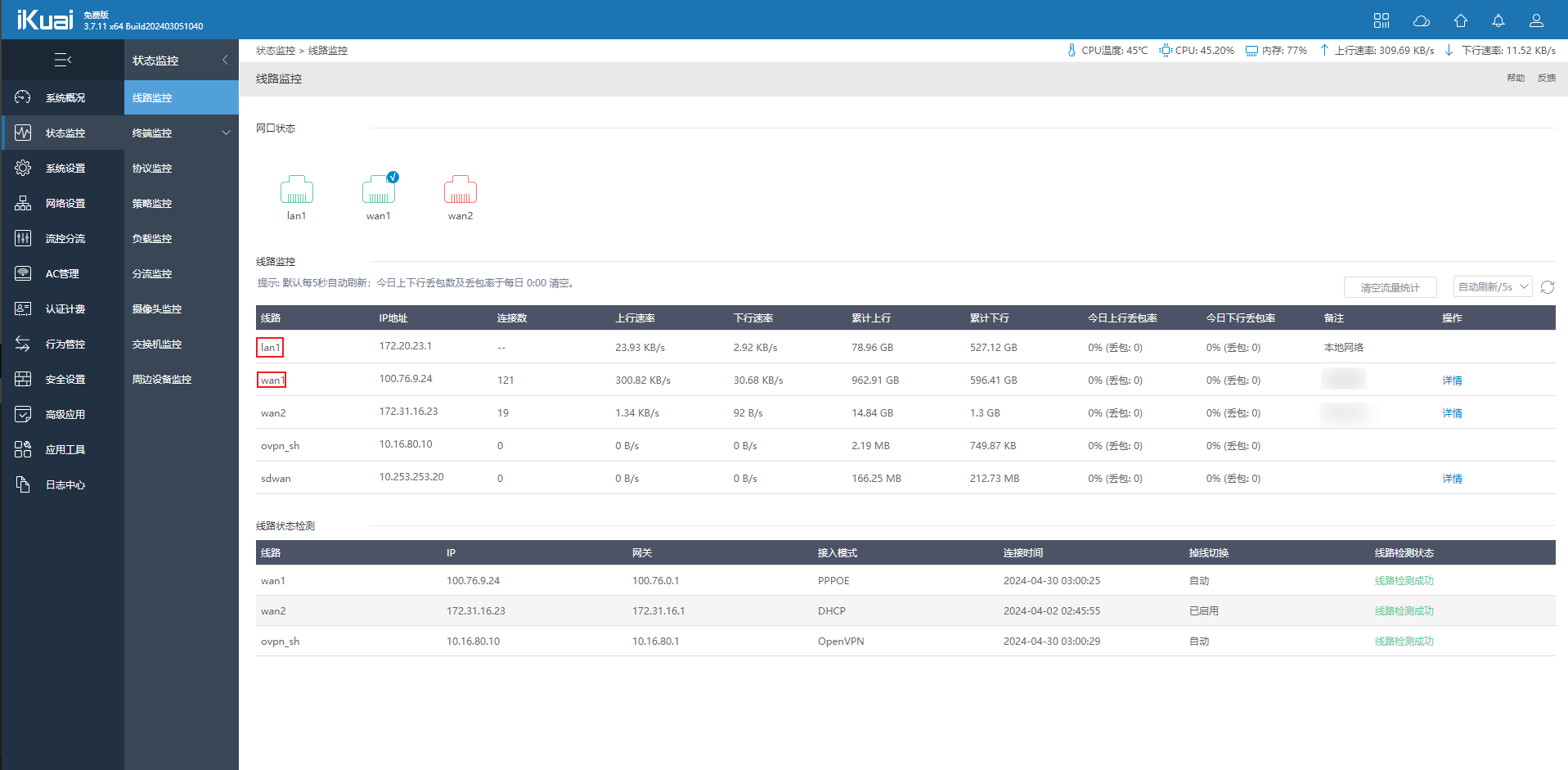
iKuai双WAN怎么使用Panabit做透明网桥呢? 前置背景主路由是iKuai,之前只有一条宽带,然后直接直接把WAN和LAN接口挂到Panabit做透明网桥就好了。最近增加了一条宽带,双WAN分流之后流只桥接一个WAN流量就不准确了。然后再官方论坛咨询了,回复是增加线路管理,但是这样我就得修改我本身的网络结构。我需要的状态是不修改我原来的网络结构,增加透明网桥监控流量就好了,所以有了一下方案。官方论坛回复,但是并不是我预期的效果。因为分流操作是在iKuai做的,按照这个操作我得调整我的网络结构。iKuai网络变动单WAN时iKuai网络接口WAN1 宽带 LAN1 局域网双WAN时iKuai网络接口WAN1 宽带1WAN3 宽带2LAN1 局域网iKuai网卡整改WAN1 宽带1WAN3 宽带2WAN4 WAN口镜像(WAN1 + WAN3)LAN1 局域网LAN2 LAN口进项(LAN1)端口镜像方案进流量LAN2 镜像 WAN1 + WAN3,方向是进。LAN2统计到的是整个网络的下行。WAN4 镜像 LAN1,方向是进。WAN4统计到的是局域网的上行。出流量LAN2 镜像 LAN1,方向是出。LAN2统计到的是局域网的下行。WAN4 镜像 WAN1 + WAN3,方向是出。WAN4统计到的是整个网络的上行。* 各有优缺点,根据自己的需求调整。如果iKuai本身下行也需要统计到,选进流量方案。如果iKuai本身的上行流量也需要统计到,选出流量方案。为什么不做双向流量的端口镜像?原因是:如果做成双向的话,Panabit看到的流量将是经过这个端口的上下之和,这就有问题了。原因在于iKuai镜像端口的流量选择上下双向之后,它把流量合并到一起了。这个问题倒是可以给iKuai反馈下。如果iKuai解决了上下双向分开。那么可以使用这个方案。覆盖上边的两个方案的数据。Panabit网卡整改Panabit不直接使用WAN1和WAN3,LAN1。而是使用WAN4和LAN2。这样就能做1对1的透明网桥。iKuai端口镜像 + Panabit透明网桥经过调整后,Panabit透明网桥成功,数据流量统计准确。修改完成

-
ZStack4.8.0我升级了 不算最早,但是也很早了。zstack还开放免费学习和考证的时候就开始用了,3.x版本。历时3年多我终于换机器升级了。ZStack4.8.0用起来更赞了先来一张主页图吧,增加了主题配色(虽然这个不是主业,但是也挺好,可以换换配色)机器内存不大,CPU也一般般,但是对我而言够用了。之前是vmware虚拟一台,然后克隆。启太多之后,工作站也卡呀。想了下,还是独立出来,就发现了ZStack。后来开始玩软路由了,买了个机器J1900,无法安装esxi。就ikuai + ikuai的kvm虚拟机,安装了op。再后来又增加了一台机器,esxi内allin。但是ZStack我还是再用创建好镜像之后,需要一台Centos,启动贼快。导出镜像之前也可以把最常用的直接安装好,然后再导出镜像。这样启动起来的机器能节省最少个把小时。创建云主机的步骤和界面竟然有点像阿里云了,对没错和阿里云有点关系。最后再看看监控大屏吧,很拉风。看着描述的花里胡哨的,你懂不懂啊,不要怀疑,我是有证的。确实描述的这些可能都不是核心,只是想记录下我升级4之后的心情。对于希望使用或者了解ZStack3( ZStack官网 已经不提供下载了)、ZStack4的可以去 官网 (有更详细的教程)。也可以看看我之前的一篇文章。对于我的用途而言就是学习或者玩(或者说测试的时候)随时启动一台机器,随时释放。搭建属于自己的云主机环境,过程、使用、都很赞。现在公司的测试机也是ZStack,不过版本是3.x版本。当你自己玩明白,能管理,出问题能解决。那么自己公司又正好需要的时候,就可以在公司玩起来了,服务器性能刚刚的。
-
-
AI:ChatGPT,假如你是Java架构师 程序员结合AI真的有点强大Q:假设你是Java架构师,请用Java语言开发一个秒杀下单接口,要求如下:1、将数据库里的商品库存预先加载到redis里存储2、下单操作时先检查redis里的商品库存是否足够扣减3、如果redis里有足够的库存就先扣减库存然后再生成订单AI:作为一个Java架构师,以下是一个简单的秒杀下单接口设计方案。首先,我们需要确保你已经安装了Redis Java客户端,例如Jedis或Redisson。这里我们使用Jedis库。请在pom.xml文件中添加以下依赖:<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>3.7.0</version> </dependency>首先,我们需要创建一个Java类来处理商品和订单:public class Product { private long id; private String name; private int stock; // 构造方法,getters和setters } public class Order { private long id; private long productId; private long userId; private int quantity; // 构造方法,getters和setters }接下来,我们将创建一个RedisUtil类,用于连接Redis并实现库存加载和查询方法:import redis.clients.jedis.Jedis; public class RedisUtil { private static final String REDIS_HOST = "localhost"; private static final int REDIS_PORT = 6379; private Jedis jedis; public RedisUtil() { this.jedis = new Jedis(REDIS_HOST, REDIS_PORT); } public void loadProductStockToRedis(Product product) { jedis.set("product_stock_" + product.getId(), String.valueOf(product.getStock())); } public int getProductStockFromRedis(long productId) { String stock = jedis.get("product_stock_" + productId); return stock == null ? -1 : Integer.parseInt(stock); } public boolean reduceProductStock(long productId, int quantity) { String script = "local stock = tonumber(redis.call('get', KEYS[1])) " + "if stock >= tonumber(ARGV[1]) then " + " redis.call('decrby', KEYS[1], ARGV[1]) " + " return true " + "else " + " return false " + "end"; return (boolean) jedis.eval(script, 1, "product_stock_" + productId, String.valueOf(quantity)); } }现在我们需要创建一个秒杀下单接口:public class SecKillService { private RedisUtil redisUtil; public SecKillService() { this.redisUtil = new RedisUtil(); } public void loadProductStockToRedis(Product product) { redisUtil.loadProductStockToRedis(product); } public Order seckillOrder(long productId, long userId, int quantity) { int stock = redisUtil.getProductStockFromRedis(productId); if (stock < quantity) { return null; } boolean success = redisUtil.reduceProductStock(productId, quantity); if (success) { // 生成订单 Order order = new Order(); order.setProductId(productId); order.setUserId(userId); order.setQuantity(quantity); // 保存订单到数据库 // saveOrderToDatabase(order); return order; } else { return null; } } }为了运行秒杀下单接口,你可以创建一个测试类:public class SecKillTest { public static void main(String[] args) { Product product = new Product(1L, "iPhone", 100); SecKillService secKillService = new SecKillService(); long userId = 12345L; int quantity = 1; // 执行秒杀下单操作 Order order = secKillService.seckillOrder(product.getId(), userId, quantity); if (order != null) { System.out.println("秒杀成功,订单信息:" + order); } else { System.out.println("秒杀失败,库存不足"); } } }Q:请继续优化接口代码,我希望接口能支撑每秒上万并发请求AI:要支持每秒上万的并发请求,我们需要进行以下优化:使用连接池优化Redis连接使用异步处理订单生成和数据库存储使用多线程来提高并发处理能力首先,我们使用Jedis连接池来优化Redis连接。更新RedisUtil类,添加一个Jedis连接池,并修改相关方法以使用连接池:import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; import redis.clients.jedis.JedisPoolConfig; public class RedisUtil { private static final String REDIS_HOST = "localhost"; private static final int REDIS_PORT = 6379; private JedisPool jedisPool; public RedisUtil() { JedisPoolConfig poolConfig = new JedisPoolConfig(); poolConfig.setMaxTotal(100); poolConfig.setMaxIdle(50); poolConfig.setMinIdle(10); poolConfig.setTestOnBorrow(true); poolConfig.setTestOnReturn(true); poolConfig.setTestWhileIdle(true); this.jedisPool = new JedisPool(poolConfig, REDIS_HOST, REDIS_PORT); } public void loadProductStockToRedis(Product product) { try (Jedis jedis = jedisPool.getResource()) { jedis.set("product_stock_" + product.getId(), String.valueOf(product.getStock())); } } public int getProductStockFromRedis(long productId) { try (Jedis jedis = jedisPool.getResource()) { String stock = jedis.get("product_stock_" + productId); return stock == null ? -1 : Integer.parseInt(stock); } } public boolean reduceProductStock(long productId, int quantity) { String script = "local stock = tonumber(redis.call('get', KEYS[1])) " + "if stock >= tonumber(ARGV[1]) then " + " redis.call('decrby', KEYS[1], ARGV[1]) " + " return true " + "else " + " return false " + "end"; try (Jedis jedis = jedisPool.getResource()) { return (boolean) jedis.eval(script, 1, "product_stock_" + productId, String.valueOf(quantity)); } } }接下来,我们需要异步处理订单生成和数据库存储。我们将在SecKillService中使用Java的CompletableFuture类实现异步处理。同时,引入一个线程池来执行异步任务:import java.util.concurrent.CompletableFuture; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class SecKillService { private RedisUtil redisUtil; private ExecutorService executorService; public SecKillService() { this.redisUtil = new RedisUtil(); this.executorService = Executors.newFixedThreadPool(50); } public void loadProductStockToRedis(Product product) { redisUtil.loadProductStockToRedis(product); } public CompletableFuture<Order> seckillOrder(long productId, long userId, int quantity) { int stock = redisUtil.getProductStockFromRedis(productId); if (stock < quantity) { return CompletableFuture.completedFuture(null); } CompletableFuture<Order> futureOrder = CompletableFuture.supplyAsync(() -> { boolean success = redisUtil.reduceProductStock(productId, quantity); if (success) { Order order = new Order(); order.setProductId(productId); order.setUserId(userId); order.setQuantity(quantity); // 模拟保存订单到数据库 // saveOrderToDatabase(order); try { Thread.sleep(100); // 模拟数据库操作耗时 } catch (InterruptedException e) { e.printStackTrace(); } return order; } else { return null; } }, executorService); return futureOrder; } }现在我们更新SecKillTest类以测试高并发场景。为此,我们将创建多个线程来模拟并发请求。import java.util.ArrayList; import java.util.List; import java.util.concurrent.CompletableFuture; import java.util.concurrent.CountDownLatch; public class SecKillTest { public static void main(String[] args) throws InterruptedException { Product product = new Product(1L, "iPhone", 100); SecKillService secKillService = new SecKillService(); secKillService.loadProductStockToRedis(product); int requestCount = 10000; CountDownLatch countDownLatch = new CountDownLatch(requestCount); List<CompletableFuture<Order>> futures = new ArrayList<>(); for (int i = 0; i < requestCount; i++) { long userId = 10000L + i; int quantity = 1; CompletableFuture<Order> futureOrder = secKillService.seckillOrder(product.getId(), userId, quantity); futures.add(futureOrder); countDownLatch.countDown(); } countDownLatch.await(); long successCount = futures.stream().filter(future -> { try { return future.get() != null; } catch (Exception e) { return false; } }).count(); System.out.println("成功秒杀的订单数:" + successCount); } }以上代码示例在每秒处理上万并发请求时应具有更高的性能。然而,还有很多其他因素需要考虑,例如Redis的性能瓶颈、网络延迟等。要实现真正的高并发,你可能需要使用更高级的技术,例如集群、分布式缓存、负载均衡等。此外,请注意,以上示例仅用于演示目的,实际项目中需要进行更多的错误处理和异常处理。此外,在实际生产环境中,建议使用分布式锁来确保库存数据的正确性。Q:我希望将方法saveOrderToDatabase改为把订单发到MQ,然后异步消费生成订单到数据库AI:要将订单发送到消息队列(MQ),我们需要选择一个消息队列服务,如RabbitMQ、Kafka等。在这个例子中,我们将使用RabbitMQ。首先,添加RabbitMQ客户端依赖到pom.xml:<dependency> <groupId>com.rabbitmq</groupId> <artifactId>amqp-client</artifactId> <version>5.13.0</version> </dependency>接下来,我们将创建一个RabbitMQUtil类来处理RabbitMQ连接和发送消息:import com.rabbitmq.client.Channel; import com.rabbitmq.client.Connection; import com.rabbitmq.client.ConnectionFactory; import java.io.IOException; import java.util.concurrent.TimeoutException; public class RabbitMQUtil { private static final String RABBITMQ_HOST = "localhost"; private static final String EXCHANGE_NAME = "order_exchange"; private static final String QUEUE_NAME = "order_queue"; private Connection connection; private Channel channel; public RabbitMQUtil() { ConnectionFactory factory = new ConnectionFactory(); factory.setHost(RABBITMQ_HOST); try { connection = factory.newConnection(); channel = connection.createChannel(); channel.exchangeDeclare(EXCHANGE_NAME, "direct"); channel.queueDeclare(QUEUE_NAME, true, false, false, null); channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "create_order"); } catch (IOException | TimeoutException e) { e.printStackTrace(); } } public void sendOrderToMQ(Order order) { try { // 使用JSON格式化订单对象,以便在消费者端进行解析 String orderJson = new ObjectMapper().writeValueAsString(order); channel.basicPublish(EXCHANGE_NAME, "create_order", null, orderJson.getBytes()); } catch (IOException e) { e.printStackTrace(); } } public void close() { try { channel.close(); connection.close(); } catch (IOException | TimeoutException e) { e.printStackTrace(); } } }现在,我们将在SecKillService类中使用RabbitMQUtil将订单发送到MQ:public class SecKillService { private RedisUtil redisUtil; private RabbitMQUtil rabbitMQUtil; private ExecutorService executorService; public SecKillService() { this.redisUtil = new RedisUtil(); this.rabbitMQUtil = new RabbitMQUtil(); this.executorService = Executors.newFixedThreadPool(50); } // 其他方法... public CompletableFuture<Order> seckillOrder(long productId, long userId, int quantity) { // ... CompletableFuture<Order> futureOrder = CompletableFuture.supplyAsync(() -> { boolean success = redisUtil.reduceProductStock(productId, quantity); if (success) { Order order = new Order(); order.setProductId(productId); order.setUserId(userId); order.setQuantity(quantity); // 发送订单到消息队列 rabbitMQUtil.sendOrderToMQ(order); return order; } else { return null; } }, executorService); return futureOrder; } }最后,我们需要创建一个消费者来监听队列并处理订单消息。新建一个OrderConsumer类:import com.rabbitmq.client.*; import java.io.IOException; public class OrderConsumer { private static final String RABBITMQ_HOST = "localhost"; private static final String EXCHANGE_NAME = "order_exchange"; private static final String QUEUE_NAME = = "order_queue"; public static void main(String[] args) throws Exception { ConnectionFactory factory = new ConnectionFactory(); factory.setHost(RABBITMQ_HOST); Connection connection = factory.newConnection(); Channel channel = connection.createChannel(); channel.exchangeDeclare(EXCHANGE_NAME, "direct"); channel.queueDeclare(QUEUE_NAME, true, false, false, null); channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "create_order"); System.out.println("Waiting for order messages..."); DeliverCallback deliverCallback = (consumerTag, delivery) -> { String orderJson = new String(delivery.getBody(), StandardCharsets.UTF_8); // 解析JSON格式的订单 ObjectMapper objectMapper = new ObjectMapper(); Order order = objectMapper.readValue(orderJson, Order.class); // 保存订单到数据库 saveOrderToDatabase(order); System.out.println("Received and processed order: " + order); }; channel.basicConsume(QUEUE_NAME, true, deliverCallback, consumerTag -> {}); } private static void saveOrderToDatabase(Order order) { // 实现订单保存到数据库的逻辑 } }现在,当SecKillService中的seckillOrder方法被调用时,订单将被发送到RabbitMQ。OrderConsumer将监听队列并在接收到订单消息后异步处理订单,将其保存到数据库。请注意,以上示例仅用于演示目的,实际项目中需要进行更多的错误处理和异常处理。此外,在实际生产环境中,建议使用分布式锁来确保库存数据的正确性。Q:我不想方法返回使用异步的CompletableFuture,正常返回就好,请继续优化代码AI:好的,我们可以将seckillOrder方法改为正常返回Order对象,而不是使用CompletableFuture。为了在不阻塞调用线程的情况下执行异步任务,我们将使用线程池executorService执行订单发送到消息队列的操作。这里是修改后的SecKillService类:public class SecKillService { private RedisUtil redisUtil; private RabbitMQUtil rabbitMQUtil; private ExecutorService executorService; public SecKillService() { this.redisUtil = new RedisUtil(); this.rabbitMQUtil = new RabbitMQUtil(); this.executorService = Executors.newFixedThreadPool(50); } // 其他方法... public Order seckillOrder(long productId, long userId, int quantity) { int stock = redisUtil.getProductStockFromRedis(productId); if (stock < quantity) { return null; } boolean success = redisUtil.reduceProductStock(productId, quantity); if (success) { Order order = new Order(); order.setProductId(productId); order.setUserId(userId); order.setQuantity(quantity); // 异步发送订单到消息队列 executorService.submit(() -> rabbitMQUtil.sendOrderToMQ(order)); return order; } else { return null; } } }现在,seckillOrder方法将直接返回Order对象,而不是CompletableFuture<Order>。同时,订单发送到消息队列的操作将在后台线程中执行,不会阻塞调用线程。这种改动会使得SecKillTest类的调用方式也有所变化,将CompletableFuture<Order>替换为Order:public class SecKillTest { public static void main(String[] args) throws InterruptedException { Product product = new Product(1L, "iPhone", 100); SecKillService secKillService = new SecKillService(); secKillService.loadProductStockToRedis(product); int requestCount = 10000; CountDownLatch countDownLatch = new CountDownLatch(requestCount); List<Order> orders = Collections.synchronizedList(new ArrayList<>()); for (int i = 0; i < requestCount; i++) { long userId = 10000L + i; int quantity = 1; executorService.submit(() -> { Order order = secKillService.seckillOrder(product.getId(), userId, quantity); if (order != null) { orders.add(order); } countDownLatch.countDown(); }); } countDownLatch.await(); long successCount = orders.size(); System.out.println("成功秒杀的订单数:" + successCount); } }请注意,以上示例仅用于演示目的,实际项目中需要进行更多的错误处理和异常处理。此外,在实际生产环境中,建议使用分布式锁来确保库存数据的正确性。Q:我现在需要保证下单接口的高可用性,如果在下单的过程中redis服务挂了应该怎么处理AI:为了确保高可用性,我们可以采取以下策略:Redis哨兵模式(Sentinel)或集群模式(Cluster):可以使用Redis的哨兵模式或集群模式来提供高可用性。在哨兵模式下,有一个主节点和多个从节点。当主节点发生故障时,哨兵将自动将其中一个从节点提升为主节点。在集群模式下,数据分布在多个节点上,当某个节点发生故障时,Redis集群将自动进行故障转移。降级策略:当Redis不可用时,我们可以将请求降级到其他缓存技术,例如本地缓存。这种情况下,可能无法实现所有功能,但可以保证服务继续运行。如果本地缓存也不可用,我们可以进一步降级到直接查询数据库,但这可能会导致性能下降。容错处理:在代码中添加异常处理和重试策略,以确保在Redis出现问题时不会导致整个应用崩溃。以下是根据上述策略修改后的SecKillService类:public class SecKillService { private RedisUtil redisUtil; private RabbitMQUtil rabbitMQUtil; private ExecutorService executorService; private ProductDao productDao; // 数据库访问对象 public SecKillService() { this.redisUtil = new RedisUtil(); this.rabbitMQUtil = new RabbitMQUtil(); this.executorService = Executors.newFixedThreadPool(50); this.productDao = new ProductDao(); // 初始化数据库访问对象 } // 其他方法... public Order seckillOrder(long productId, long userId, int quantity) { int stock = -1; try { stock = redisUtil.getProductStockFromRedis(productId); } catch (Exception e) { // Redis异常处理 System.err.println("Redis异常,尝试从数据库获取库存"); stock = productDao.getProductStockFromDatabase(productId); } if (stock < quantity) { return null; } boolean success = false; try { success = redisUtil.reduceProductStock(productId, quantity); } catch (Exception e) { // Redis异常处理 System.err.println("Redis异常,尝试直接从数据库扣减库存"); success = productDao.reduceProductStockInDatabase(productId, quantity); } if (success) { Order order = new Order(); order.setProductId(productId); order.setUserId(userId); order.setQuantity(quantity); // 异步发送订单到消息队列 executorService.submit(() -> rabbitMQUtil.sendOrderToMQ(order)); return order; } else { return null; } } }请注意,以上示例仅用于演示目的,实际项目中需要进行更多的错误处理和异常处理。此外,在实际生产环境中,建议使用分布式锁来确保库存数据的正确性。Q:我希望你这么来处理,如果下单过程中redis服务挂了,我们可以讲本次请求存储在本地缓存或文件里,然后定时重试尝试访问redis,如果redis恢复了,我们继续下单AI:在这种情况下,我们可以为失败的请求设置一个本地缓存队列或文件存储,当Redis恢复时,重新尝试处理这些请求。以下是修改后的SecKillService类:import java.util.concurrent.ConcurrentLinkedQueue; public class SecKillService { private RedisUtil redisUtil; private RabbitMQUtil rabbitMQUtil; private ExecutorService executorService; private ConcurrentLinkedQueue<SecKillRequest> failedRequestsQueue; public SecKillService() { this.redisUtil = new RedisUtil(); this.rabbitMQUtil = new RabbitMQUtil(); this.executorService = Executors.newFixedThreadPool(50); this.failedRequestsQueue = new ConcurrentLinkedQueue<>(); retryFailedRequests(); } // 其他方法... public Order seckillOrder(long productId, long userId, int quantity) { int stock = -1; try { stock = redisUtil.getProductStockFromRedis(productId); } catch (Exception e) { // Redis异常处理 System.err.println("Redis异常,将请求添加到失败队列中"); failedRequestsQueue.add(new SecKillRequest(productId, userId, quantity)); return null; } if (stock < quantity) { return null; } boolean success = false; try { success = redisUtil.reduceProductStock(productId, quantity); } catch (Exception e) { // Redis异常处理 System.err.println("Redis异常,将请求添加到失败队列中"); failedRequestsQueue.add(new SecKillRequest(productId, userId, quantity)); return null; } if (success) { Order order = new Order(); order.setProductId(productId); order.setUserId(userId); order.setQuantity(quantity); // 异步发送订单到消息队列 executorService.submit(() -> rabbitMQUtil.sendOrderToMQ(order)); return order; } else { return null; } } private void retryFailedRequests() { ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1); scheduledExecutorService.scheduleAtFixedRate(() -> { if (!failedRequestsQueue.isEmpty()) { System.out.println("尝试重新处理失败的请求"); SecKillRequest request; while ((request = failedRequestsQueue.poll()) != null) { seckillOrder(request.getProductId(), request.getUserId(), request.getQuantity()); } } }, 0, 10, TimeUnit.SECONDS); } }我们创建了一个名为failedRequestsQueue的并发队列来存储失败的请求。在seckillOrder方法中,当Redis异常时,我们将请求添加到失败队列中。然后,我们创建了一个定时任务retryFailedRequests,它每隔一段时间(例如,10秒)尝试重新处理失败的请求。如果Redis恢复,这些请求将被重新处理并正常下单。另外,我们需要创建一个SecKillRequest类来存储失败的请求:public class SecKillRequest { private long productId; private long userId; private int quantity; public SecKillRequest(long productId, long userId, int quantity) { this.productId = productId; this.userId = userId; this.quantity = quantity; } public long getProductId() { return productId; } public long getUserId() { return userId; } public int getQuantity() { return quantity; } }注意,以上示例仅用于演示目的,实际项目中需要进行更多的错误处理和异常处理。此外,在实际生产环境中,建议使用分布式锁来确保库存数据的正确性。在实际项目中,你可能需要考虑以下优化和改进:对请求队列的大小进行限制,以防止内存耗尽。如果队列已满,可以选择拒绝新的请求,或者将它们存储到磁盘中的文件中。在定时任务中添加异常处理,以防止定时任务因为单个请求的问题而中断。可以考虑将失败的请求存储在磁盘中的文件里,这样即使应用程序重启,也可以从文件中恢复失败的请求。为了确保请求在Redis不可用期间不会丢失,可以在请求被处理之前将其从队列中移除,然后将处理后的请求存储在另一个队列中。这样,如果在处理过程中发生故障,可以在故障恢复后重新处理这些请求。在实际项目中,你可能需要监控Redis的状态,以便在Redis出现问题时,可以及时通知相关人员进行处理。这可以通过第三方监控工具或自定义的监控解决方案来实现。为了提高系统的可扩展性和可维护性,可以将定时任务和秒杀服务分离,部署在不同的应用程序或微服务中。这样,即使定时任务出现问题,也不会影响到秒杀服务的正常运行。Q:请继续生成下异步消费mq生成订单的代码AI:为了实现异步消费MQ生成订单的功能,首先需要创建一个新的订单消费者类OrderConsumer。这个类需要实现一个方法consumeOrderMessage,该方法将从MQ中读取消息并生成订单。接着,我们将创建一个新的线程或线程池来异步处理这些消息。以下是创建OrderConsumer类的代码:import com.rabbitmq.client.Channel; import com.rabbitmq.client.Connection; import com.rabbitmq.client.ConnectionFactory; import com.rabbitmq.client.DeliverCallback; public class OrderConsumer { private final RabbitMQUtil rabbitMQUtil; private final OrderDao orderDao; public OrderConsumer() { this.rabbitMQUtil = new RabbitMQUtil(); this.orderDao = new OrderDao(); } public void consumeOrderMessage() throws IOException, TimeoutException { ConnectionFactory factory = rabbitMQUtil.getConnectionFactory(); Connection connection = factory.newConnection(); Channel channel = connection.createChannel(); channel.queueDeclare(RabbitMQUtil.ORDER_QUEUE_NAME, true, false, false, null); DeliverCallback deliverCallback = (consumerTag, delivery) -> { byte[] messageBodyBytes = delivery.getBody(); Order order = (Order) rabbitMQUtil.deserialize(messageBodyBytes); if (order != null) { orderDao.saveOrderToDatabase(order); System.out.println("订单已保存到数据库: " + order); } channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false); }; channel.basicConsume(RabbitMQUtil.ORDER_QUEUE_NAME, false, deliverCallback, consumerTag -> {}); } }现在,我们需要修改SecKillTest类,以便启动一个新的线程来异步消费订单消息:public class SecKillTest { public static void main(String[] args) throws InterruptedException { Product product = new Product(1L, "iPhone", 100); SecKillService secKillService = new SecKillService(); secKillService.loadProductStockToRedis(product); // 启动订单消费者线程 OrderConsumer orderConsumer = new OrderConsumer(); Thread orderConsumerThread = new Thread(() -> { try { orderConsumer.consumeOrderMessage(); } catch (IOException | TimeoutException e) { e.printStackTrace(); } }); orderConsumerThread.start(); int requestCount = 10000; CountDownLatch countDownLatch = new CountDownLatch(requestCount); List<Order> orders = Collections.synchronizedList(new ArrayList<>()); for (int i = 0; i < requestCount; i++) { long userId = 10000L + i; int quantity = 1; executorService.submit(() -> { Order order = secKillService.seckillOrder(product.getId(), userId, quantity); if (order != null) { orders.add(order); } countDownLatch.countDown(); }); } countDownLatch.await(); long successCount = orders.size(); System.out.println("成功秒杀的订单数:" + successCount); } }这样,在SecKillTest类中,我们启动了一个新的线程orderConsumerThread,用于异步消费订单消息。当从MQ中接收到订单消息时,OrderConsumer类的consumeOrderMessage方法将调用OrderDao的saveOrderToDatabase方法来保存订单到数据库。请注意,以上示例仅用于演示目的,实际项目中需要进行更多的错误处理和异常处理。此外,为了确保系统的可扩展性和可维护性,可以将订单消费者和秒杀服务分离,部署在不同的应用程序或微服务中。这样,即使订单消费者出现问题,也不会影响到秒杀服务的正常运行。在实际项目中,你可能需要考虑以下优化和改进:为了确保消息处理的可靠性,可以使用RabbitMQ的ACK(确认)机制。在OrderConsumer类中,我们已经添加了basicAck方法来确认消息已经成功处理。如果处理失败,可以使用basicNack或basicReject方法来拒绝消息,这样消息会被重新入队并等待处理。为了提高消息处理的并发性能,可以使用多个消费者同时处理消息。这可以通过创建多个线程或使用线程池来实现。可以使用RabbitMQ的负载均衡和集群功能,以确保消息队列服务的高可用性和可扩展性。在实际项目中,建议使用更高级的消息队列中间件,例如Apache Kafka或Apache Pulsar,它们提供了更多的可靠性和扩展性特性。为了确保MQ中的消息在应用程序重启后不会丢失,可以将RabbitMQ配置为持久化消息。这可以通过将queueDeclare方法的durable参数设置为true来实现。在实际项目中,你可能需要监控消息队列的状态和性能,以便在出现问题时,可以及时通知相关人员进行处理。这可以通过第三方监控工具或自定义的监控解决方案来实现。
-
使用docker-compose搭建elk 概要步骤:1、准备logstash配置文件2、准备kibana配置文件3、准备docker-compose.yml4、启动并验证1、准备logstash配置文件# 在etc下创建配置文件目录 mkdir -p /etc/logstash/{config,pipeline} # 创建pipelines.yml touch /etc/logstash/config/pipelines.yml cat>/etc/logstash/config/pipelines.yml<<EOF - pipeline.id: api-main path.config: /usr/share/logstash/pipeline/logstash-api-main.conf pipeline.workers: 3 - pipeline.id: edge-main path.config: /usr/share/logstash/pipeline/logstash-edge-main.conf pipeline.workers: 3 - pipeline.id: xtl-server path.config: /usr/share/logstash/pipeline/logstash-xtl-server.conf pipeline.workers: 3 EOF # 分别创建 conf # 创建logstash-api-main.conf文件 touch /etc/logstash/pipeline/logstash-api-main.conf # 写入文件内容 cat>/etc/logstash/pipeline/logstash-api-main.conf<<EOF input { tcp { mode => "server" host => "0.0.0.0" port => 4560 codec => json_lines } } output { elasticsearch { hosts => "es:9200" index => "api-main-logstash-%{+YYYY.MM.dd}" } } EOF # 创建logstash-edge-main.conf文件 touch /etc/logstash/pipeline/logstash-edge-main.conf # 写入文件内容 cat>/etc/logstash/pipeline/logstash-edge-main.conf<<EOF input { tcp { mode => "server" host => "0.0.0.0" port => 4561 codec => json_lines } } output { elasticsearch { hosts => "es:9200" index => "edge-main-logstash-%{+YYYY.MM.dd}" } } EOF # 创建logstash-xtl-server.conf文件 touch /etc/logstash/pipeline/logstash-xtl-server.conf # 写入文件内容 cat>/etc/logstash/pipeline/logstash-xtl-server.conf<<EOF input { tcp { mode => "server" host => "0.0.0.0" port => 4562 codec => json_lines } } output { elasticsearch { hosts => "es:9200" index => "xtl-server-logstash-%{+YYYY.MM.dd}" } } EOF2、准备kibana配置文件# 创建配置文件夹 mkdir -p /etc/kibana/config # 创建配置文件 touch /etc/kibana/config/kibana.yml # 写入文件内容 cat>/etc/kibana/config/kibana.yml<<EOF server.host: '0.0.0.0' server.shutdownTimeout: '5s' elasticsearch.hosts: ['http://elasticsearch:9200'] monitoring.ui.container.elasticsearch.enabled: true EOF3、准备docker-compose.yml# 创建文件夹 mkdir -p /etc/docker-compose/ # 创建文件 touch /etc/docker-compose/docker-compose-elk.yml # 写入文件内容(网络部分注释原因:如果单独部署ELK需要开启,和其他编排使用编排网络) cat>/etc/docker-compose/docker-compose-elk.yml<<EOF version: '3.2' services: elasticsearch: image: elasticsearch:7.17.4 volumes: - /etc/localtime:/etc/localtime - /data/elasticsearch/plugins:/usr/share/elasticsearch/plugins #插件文件挂载 - /data/elasticsearch/data:/usr/share/elasticsearch/data #数据文件挂载 expose: - 9200 - 9300 ports: - '9200:9200' - '9300:9300' container_name: elasticsearch restart: always environment: - 'cluster.name=elasticsearch' #设置集群名称为elasticsearch - 'discovery.type=single-node' #以单一节点模式启动 - 'ES_JAVA_OPTS=-Xms1024m -Xmx1024m' #设置使用jvm内存大小 networks: - wsd_net privileged: true logstash: image: logstash:7.17.4 container_name: logstash restart: always volumes: - /etc/localtime:/etc/localtime - /etc/logstash/config/pipelines.yml:/usr/share/logstash/config/pipelines.yml - /etc/logstash/pipeline/logstash-api-main.conf:/usr/share/logstash/pipeline/logstash-api-main.conf - /etc/logstash/pipeline/logstash-edge-main.conf:/usr/share/logstash/pipeline/logstash-edge-main.conf - /etc/logstash/pipeline/logstash-xtl-server.conf:/usr/share/logstash/pipeline/logstash-xtl-server.conf expose: - 5044 - 5000 - 9600 - 4560 - 4561 - 4562 ports: - '5044:5044' - '5000:5000/tcp' - '5000:5000/udp' - '9600:9600' - '4560:4560' - '4561:4561' - '4562:4562' environment: LS_JAVA_OPTS: -Xms1024m -Xmx1024m TZ: Asia/Shanghai # MONITORING_ENABLED: false links: - elasticsearch:es #可以用es这个域名访问elasticsearch服务 networks: - wsd_net depends_on: - elasticsearch privileged: true kibana: image: kibana:7.17.4 container_name: kibana restart: always volumes: - /etc/localtime:/etc/localtime - /etc/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml expose: - 5601 ports: - '5601:5601' links: - elasticsearch:es #可以用es这个域名访问elasticsearch服务 environment: - ELASTICSEARCH_URL=http://elasticsearch:9200 #设置访问elasticsearch的地址 - 'elasticsearch.hosts=http://es:9200' #设置访问elasticsearch的地址 - I18N_LOCALE=zh-CN networks: - wsd_net depends_on: - elasticsearch privileged: true #networks: # elk: # name: elk # driver: bridge # ik 分词器的安装 # 集群 docker-compose exec elasticsearch elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.4/elasticsearch-analysis-ik-7.17.4.zip # 单点 bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.4/elasticsearch-analysis-ik-7.17.4.zip # EOF4、启动并验证# 进入docker-compose编排配置文件 cd /etc/docker-compose # 启动 docker-compose -f docker-compose.yml -f docker-compose-elk.yml up -d elasticsearch logstash kibana请求并验证假设服务器为172.28.0.161浏览器访问http://172.28.0.161:5601页面上加入演示数据验证springboot接入elk日志
-
Centos7 LVM卷扩容 1、检查新硬盘是否已识别2、创建物理卷:将新硬盘创建为物理卷(假设新硬盘设备名称为/dev/sdb)3、将物理卷添加到卷组:将新创建的物理卷添加到卷组4、扩展逻辑卷:根据需求将逻辑卷扩展为所需大小5、查看逻辑卷扩展是否成功# 检查新硬盘是否已识别 fdisk -l # 创建物理卷 pvcreate /dev/sdb # 将物理卷添加到卷组 # 1、查看卷组名称(VG Name) vgdisplay # 2、假设卷组名称为centos vgextend centos /dev/sdb # 3、查看卷组名称(检验是否键入成功) vgdisplay # 扩展逻辑卷 # 1、扩展 /data 逻辑卷为60%: lvextend -r -l +60%FREE /dev/centos/data # 2、扩展 / 逻辑卷为20-25%: lvextend -r -l +20%FREE /dev/centos/root # 3、扩展 /home 逻辑卷为10-15%: lvextend -r -l +10%FREE /dev/centos/home # 4、扩展 /boot 逻辑卷为所需大小,例如20G(根据实际大小修改): lvextend -L +20G /dev/centos/boot # 5、扩展 /swap 逻辑卷为所需大小,例如16G(根据实际大小修改): lvextend -L +16G /dev/centos/swap # 查看逻辑卷扩展是否成功 lvdisplay df -hT